In Artificial Intelligence, it is important to measure the quality of the data we are trying to use.
For instance, if we want to classify a cervix image according to the degree of cancer, how do we know if that image follows the acquisition protocol and can be used for diagnosing the patient [1] so that we can trust our prediction? In another domain, if we want to classify the topic of a given text (which may be written in colloquial language), how do you know if the text is useful/has good quality?
In Machine Learning, there’s a common saying that Garbage-in Garbage-out. Models are as good as the data they consume
Image quality estimation is a tough problem since quality is dependent on the user and the task itself. This is of special interest when we measure quality according to several factors and use it to make decisions (e.g., efficiency, durability, price of something).
We have previously faced the issue of objective quality estimation in several areas (image/text) and industries (TelCo, healthcare). In this blog post, we will discuss some alternatives from the Data Science community, as well as a methodology we have successfully used in the past to estimate data quality without supervision on the quality task.
What’s out there?
Quality Assessment research’s goal, up until now, has been to make quality predictions that are in agreement with the opinion of human observers. Quality measurement is typically done using very subjective labels – something of good quality to an observer can be of bad quality to another.
For instance, in [2], Convolutional Neural Networks are used for predicting subjective image quality in databases such as the LIVE Image Quality Assessment Database, using human-assessed quality labels.
Some unsupervised approaches [3] also group image quality metrics into several groups, such as compression artifacts, image noise, color artifacts, blur, and distortions. However, these approaches focus on a “technical” view of quality (signal quality) instead of a semantic/human perception. In the text domain [4], a set of automatic rules is defined for Software Documentation Quality which is mostly based on human readability and ease of implementation.
All these previously mentioned approaches have been applied with some success, but most focus on quantifying data acquisition errors. In some domains, such as the medical domain, it is important to have semantic knowledge of quality. As an example, in retinal fundus images, a common metric is the Image Structure Clustering (ISC). ISC assesses a correct distribution of pixel intensities corresponding to the relevant anatomical structures present in the retina [5].
However, creating such metrics and having them accepted by the researchers’ community is not feasible for each area, with lots of domain-specific rules. Besides, most methods for quality measurement are focused on a specific modality: images.
In this blog post, we propose a way to objectively measure the quality of any modality (image, text, tabular data), for both classification and regression problems and give a few use cases in which we can use this.
General Methodology
Let’s suppose we are trying to classify a given sample (e.g. an image or a document), and we want to objectively measure the quality of that sample.
We can consider that a good quality sample is the one reaches high scores in a secondary target task (e.g., classifying samples’ class, properly estimating a regression value, segmenting the image, etc.).
We have some semantic knowledge of quality for a given domain by modeling quality as task-specific, but that is generalizable for any problem.
For instance, in Customer Service, we can measure how informative a client’s technical issue description is to understand what happened with the client or to understand how close he is to churn (leaving the service). For medical images, we can measure how good an image is for classifying a certain form of cancer (which can depend on illumination conditions, domain-specific artifacts, etc.).
The first step has a model that can estimate the probability of that sample belonging to a certain class (discriminative model) or a regression model that estimates a continuous output.
We can then calculate the error associated with that estimation with the metric of interest. For instance, as in a classification task or by the absolute error/squared error in a regression task. We can have an error associated with each instance by saving the out-of-fold predictions.
We then need a second model that tries to predict the error using the sample as an input to automatically estimate sample quality.
Samples with higher error as an output of the second model will have lower quality, and therefore be more prone to having worse performance as an output of the first model.
Image Quality in Fashion-MNIST
Fashion-MNIST is a dataset of 60k 28×28 grayscale images of 10 fashion categories, along with a test set of 10,000 images, available in Keras’ datasets. We chose two classes to illustrate our approach for quality estimation (T-shirt/top vs trousers). How can we estimate the quality of this binary classification problem?
Initially, both train and test splits were concatenated, as we intend to calculate out-of-fold errors.
For simplicity, we introduced random zoom-in with a scale factor that can be manipulated to simulate the aggressiveness of our approach (in this case, a range of 0.5-0.9 was used from Keras’ ImageDataGenerator). The higher the scale factor, the more disrupted the image can be. With too low-scale factors, the image might not have changed at all. On the other hand, if the scale factor is too high, the images lose their meaning. However, you don’t need to apply data augmentation in a real-life setting. Instead, you can simply use your original images with quality variations as input.
Below, 8 images were randomly chosen before and after adding noise.
Model 1: Classifying samples
We used a standard VGG-like CNN for classifying the samples.
The out-of-fold sample error was calculated using 5-Fold Cross-Validation.
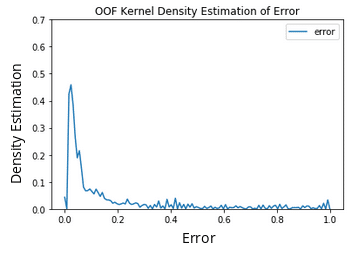
The next figure shows the Kernel Density Estimation of the model’s error. It can be seen that the model managed to obtain a low error on most of the samples since this is a binary classification problem that uses a relatively simple dataset, but there are some samples with high error.
Model 2: Estimating sample error
We attempted to create a model that could calculate sample error from the out-of-fold errors. The out-of-fold samples were randomly split into 30% test, and 70% train, and a similar architecture was applied, with a sigmoid activation and binary cross-entropy loss. MSE was not used as binary cross-entropy was found to have better convergence, and our output is between 0 and 1.
The Spearman Rank was 44%, showing that we can properly estimate the classification error and its monotonicity by having only an image.
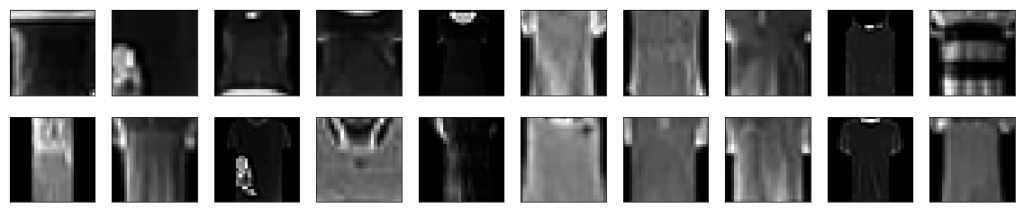
Below, the images the model considered to have the worst quality (highest estimated error) are shown.
It can be seen that these are images with bad acquisition conditions and with misleading shapes. Even the human eye has difficulty distinguishing both classes (top/trousers vs. pants) in some of the images.
Next, the images the model considered to have the best quality (lowest estimated error) are shown. Note that since this is an unbalanced regression problem, most of the images will have low error and the example shown below is not fully representative of the whole “good quality” examples.
The higher quality images – t-shirts – are the ones that follow a standard “image acquisition protocol” and follow overall image patterns.
We then performed another experiment by removing the images with artificial data augmentation and re-training the whole process. In this new process, the images with the highest error are the following:
Once again, lower-quality images had similar behavior to the previous example. On the other hand, the images with lowest error are the following:
These images are also very similar to the ones presented below. The model managed to ignore the patterns of the t-shirts’ drawings and assumed the quality was good if the visible shape followed the “standards” of low-error images in the training set.
Discussion
We have created a domain-independent approach for estimating sample error in classification problems without relying on subjective human annotations.
In the literature, three approaches were previously shown: supervised, unsupervised and domain-specific. We can frame our approach as weakly supervised since we have a proxy of quality labels, and the errors on the task itself.
While the proposed approach has the main advantage of not requiring human labels, it has a few disadvantages. In some cases, we can have a low error, which can mislead the model into thinking that a bad image has high quality or vice-versa. Some cases in which this can occur are:
Low-quality class labels
Areas with low density (i.e., less frequent types of images) which the model wasn’t able to learn correctly
Cases that are difficult to learn and could have issues in the future (such as visually degraded images), but the model was good enough to discriminate them from the other class.
There are alternative approaches for measuring quality that are not described here.
Since this is not a generative model, we cannot fix the problem of possibly having high error in low-density areas with good quality data since we do not know if we are in such areas. We can either pair our current model with another generative model or think about a different architecture.
Using generative models, we can frame quality assessment as an anomaly detection problem. For instance, assuming the dataset has few bad-quality samples, we can learn its distribution. The lower the density of new samples, the worse their quality will be (or the more non-compliant).
Costa, P., Galdran, A., Meyer, M. I., Abràmoff, M. D., Niemeijer, M., Mendonça, A. M., & Campilho, A. (2017). Towards adversarial retinal image synthesis. arXiv preprint arXiv:1701.08974.
Like this story?
Subscribe to Our Newsletter
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
Transform Your Growth with custom ai software development in 2026
Apr 1, 2026 in
Guide: Explainer
Explore how custom ai software development can boost efficiency, cut costs, and deliver measurable value - find trusted partners and practical steps for 2026.
Discover how AI for customer service can transform your support operations. Learn practical strategies to reduce costs, improve satisfaction, and drive growth.
How Might We Statements: Turn Challenges into Opportunities
Mar 15, 2026 in
Guide: Explainer
Discover how might we statements transform complex challenges into real opportunities. Learn practical crafting tips, workshops, and real-world examples.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.

 in a classification task or by the absolute error/squared error in a regression task. We can have an error associated with each instance by saving the out-of-fold predictions.
in a classification task or by the absolute error/squared error in a regression task. We can have an error associated with each instance by saving the out-of-fold predictions.