In recent years, the e-commerce industry has been increasing significantly in several sectors like food, retailing, and electronics. In the latter part of 2020, this increase has been even higher with growth 3 times greater than the previous years, mostly due to the pandemic context we live in, which boosted the number of online shopping.
Due to this increase in online shopping, the distributor’s logistics in the deliveries have been put to test, to maintain the successful delivery of a greater number of orders in the expected time. As a direct consequence, the number of complaints relative to online orders has also increased significantly (44% more complaints than last year), the most common reason being the delay in delivery.
There are different reasons that lead to an unsuccessful delivery, one of which is an incorrect or incomplete address. Thus, in this blog, different solutions for validating the provided addresses are discussed, with the goal of maximizing the probability of successful deliveries.
Historical data to consider
In order for a given order to be considered successful, it must be delivered on time to the correct person, using the information provided by the customers when placing the order. This information, which is the input data, is exemplified in the following Table:
Address and ZIP code validation
One way to improve the delivery efficiency is to validate the provided address and ZIP code before starting the deliveries course, in order to assure that the address is not misspelled and there is not any relevant information missing.
Address Validation:
The address itself can be challenging to validate as it can have a more fuzzy format, therefore, two different types of approaches are presented:
Supervised solution
Self-supervised solution
The first step, which is useful in both supervised and self-supervised approaches, is to extract relevant features from the provided addresses (and ZIP codes), as input to the models. These features are:
Street name
Street number
Door number (if it is a building)
District name
Person to receive delivery
A suitable method for extracting these kinds of features from address text can be to use Named Entity Recognition for identifying the different name entities, like door number, person name, or organization. For more stable formats (e.g., zip code), regular expressions can also be a viable solution, where we define the rules for the format we are expecting. There are already some packages for address parsing like libpostal and pyap.
Having the features extracted from the data, we can apply different approaches for the validation of the provided addresses.
Supervised solution
In this first approach, the goal is to train a model capable of predicting if a given address is correct or not (due to incomplete or inaccurate information) based on the success history of previous deliveries. Using supervised learning, we can follow two different methodologies: Traditional Machine Learning and Deep Learning.
Traditional Machine Learning
Using a more traditional view of learning, we can first perform feature extraction and feed the resulting features to a Machine Learning model that will predict the correctness of a given address.
Besides the address features, there are two other features that can be relevant to determine the success of the delivery: Building typology and Area type.
Building typology feature
This feature determines whether the address corresponds to a house or an apartment, which can be a piece of important information for the models.
A simple and manual solution would be to use Google Maps API to see if the extracted door number of a specific street name corresponds to an apartment or a house.
Another solution could be to analyze the deliveries history for the same address (door number + street name) and if the total number of deliveries is significantly higher than the average, it should be an indicator that it refers to an apartment or office space, if it significantly lower it may point to it being a house.
Area type feature
Determining whether the delivery is to a residential or a commercial/industrial area can also have an influence on the success of the delivery. This information should also be another feature of the input data. For instance, if it is an office address then the information about the person to receive the package may be more relevant.
A nearest neighbor approach would be suitable for extracting this information, as, logically, if the neighboring buildings correspond to residential houses, there is a high probability of the address in question also being residential.
Hence, based on the street name and door number, we can identify the closest neighbors, and if the majority of them are commercial/industrial then we are referring to a commercial/industrial address, otherwise, it would be assumed to be a residential address.
Target
As our model aims to predict whether a given address is correct or not, only the successful deliveries and the unsuccessful deliveries due to addresses not found are relevant, the other deliveries should be filtered out (based on the Delivery Status field of our original dataset).
Hence, based on the different features considered, our input data could be represented as next:
Door number*: If it is None or empty, it means it is a house, otherwise it is in an apartment block.
For the modeling part, we should use a Classification model (e.g., Logistic Regression or SVM), as we have a binary output.
Deep Learning
Instead of using a traditional machine learning model, we can choose to explore a deep learning approach to predict whether a given address is correct or not.
In this case, there is no feature extraction step. We feed directly the addresses of past deliveries to a Recurrent Neural Network (character-wise) and it will learn to represent each address (set of sequential characters) internally, mapping it to the respective target.
Although these two views, traditional machine learning and deep learning, were presented separately, they can always be combined using ensemble methods (e.g., model stacking or averaging).
Self-Supervised solution
In this second approach, a self-supervised solution is used, where the idea is, given a set of addresses from the database, perform data augmentation techniques for text and give that information as the target so that a supervised model can learn to differentiate valid from incorrect addresses.
Random Insertion: Addition of new words to the addresses. These can be randomly selected or can be pieces from other valid addresses.
Random Swapping: Random swapping of text characters, this can be performed at a character or word level. Moreover, the swapping can be done within the same address, or by combining different valid addresses.
Random Deletion: Random deletion of characters or words from a given address.
Duplicates Insertion: Add duplicate words to the addresses, increasing their noise.
Synonyms Replacement: Replace some words with their synonyms. An example would be replacing Street with Road.
We have used these techniques on a previous project here.
To ensure that we are augmenting valid addresses, only the addresses that led to successful deliveries should be used as input, for the data augmentation step.
The Figure below illustrates an example of data augmentation, for the dataset generation:
After self-generating the target, we can train a supervised model (binary classification) to detect if a given address is correct or not, where the input would be similar to the Table shown previously.
The ZIP code can be easily validated as it has a predefined format (e.g., 1234 – 567). Hence, we can search a database with all known ZIP codes and look for a match that can validate the provided ZIP code.
If no match is found, we can compare each known ZIP code with the one provided, and assess its similarity using specific criteria like the Levenshtein distance or cosine similarity of N-Grams or word embeddings. The one most similar to the provided ZIP code is the strongest candidate for the true ZIP code.
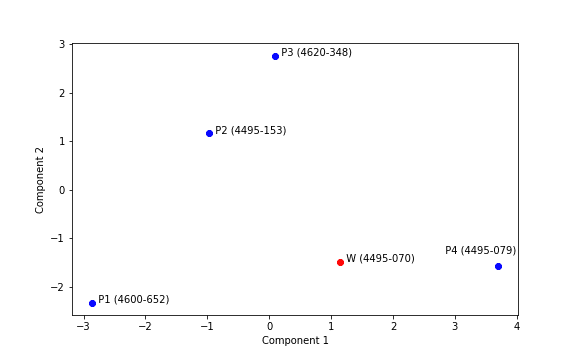
Next, an example is provided where a given misspelled ZIP code (W) is corrected using the distance between word embeddings of 4 other valid ZIP codes. The Figure below illustrates each ZIP code as a vector of two dimensions, obtained from the word embedding (after dimensionality reduction):
As we can see from the Figure the invalid ZIP code (red point) is closer to P4 than to any other data point, which indicates that P4 should be the correct ZIP code.
Optimization
Validating the addresses before performing the deliveries should help optimizing the delivery success rate, nevertheless there are some criteria to take into consideration when analyzing the result of the addresses validations, namely:
Cost of performing the delivery, based on distance and time.
Cost of confirming, through a phone call, that the address is correct. Moreover, there is also a probability of performing the call and not getting the address confirmed (e.g., call not answered).
Confidence in the address validation prediction.
In this case, the prediction confidence helps measuring the need of a confirmation call, based on the distance to the delivery address. If the address validation confidence is high then the cost of a confirming call can be avoided, regardless of the distance to the target. But if the confidence of the prediction is low then a compromise between the delivery cost and the confirmation call cost should exist. The higher the distance to the delivery target, the higher the relevance and value of performing a confirmation phone call will be, even having the possibility of not getting it confirmed.
The goal of this step is to minimize the overall cost associated with a given action, by considering the need of a confirmation call based on the respective confirmation probability, distance and address validation confidence.
The goal in this blog was to discuss a solution for validating delivery addresses, in order to maximize the probability of a successful delivery.
We started by analyzing the input data most suitable for this context and which features may be relevant. Then, we explored different techniques for validating addresses and ZIP codes provided by clients when filling ordering forms.
For the addresses validation, we described two different approaches, a supervised approach in which we present two different visions for detecting whether a given address is valid or not: traditional machine learning and deep learning. The second approach was a self-supervised model, where data augmentation allowed the self-labeling of data, in order to predict if a given address is valid or not. With regards to ZIP code validation, we presented a simple similarity-based technique using the addresses word embedding for comparing different ZIP codes affinity.
Finally, the analysis of the relevance of address validation for minimizing the overall costs involved was discussed.
If you have other ideas about how to validate addresses, make sure to reach us!
Like this story?
Subscribe to Our Newsletter
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
Generative AI Implementation Roadmap for Business Success
Jul 27, 2026 in
Guide: How-to
Follow a step-by-step Generative AI Implementation roadmap to align resources, integrate models, and secure strong ROI in your enterprise projects.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.