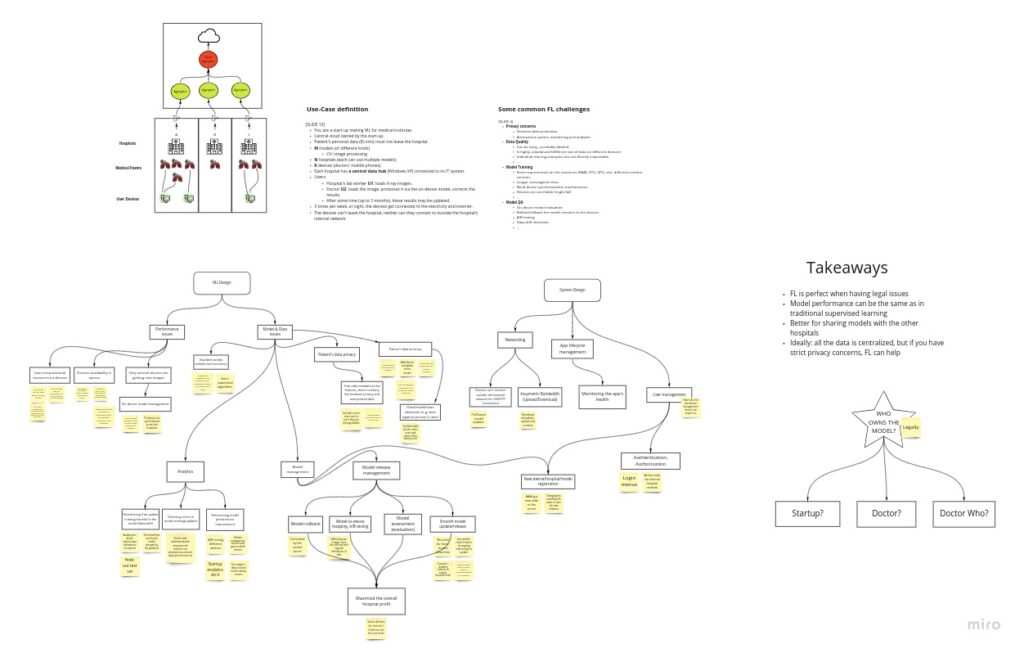
NILG.AI, together with Neu.ro decidedto try a format similar to a Reading Club, where the topic is not a specific paper but an entire research area. After a short discussion, we had a System Design part where the team described a specific use case to apply the new approach. Ideally, the discussion would stick to the format of a typical System Design interview — however, our first exploratory attempt appeared to be rather a freestyle.
In our Session #1, held on 2021–05–27, an ML team from NILG.AI led by Paulo Maia, and an MLOps team from Neu.ro led by Artem Yushkovsky met. The leaders researched the topic preliminarily and prepared a theoretical presentation for ~30-min so that everyone could be on the same page. Then, we had a ~90-minute practical part where both teams discussed technical aspects (both ML and MLOps) of the architecture for a given use-case, putting their thoughts to a Miro board.
The outcomes are shared in a Medium article (7-10 min read), where you can see a high-level overview of the outcomes of this session and the takeaways.
Let us know if you have any comments about this topic!
Like this story?
Subscribe to Our Newsletter
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
Business Transformation Strategy: Your 2026 Guide
Jul 7, 2026 in
Guide: Explainer
Master your business transformation strategy with our 2026 guide. Learn to execute AI roadmaps, avoid pitfalls, and drive growth.
A Strategic Guide to Generative AI for Business Transformation
Jul 1, 2026 in
Guide: Explainer
Unlock real growth with our guide to generative AI for business transformation. Learn to build a roadmap, find high-value use cases, and measure your AI ROI.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.