AI4tech • Information Retrieval • Machine Learning • NLP •
Duplicate detection in text data
An overview of my internship at NILG.AI
Beatriz Santos on Oct 25, 2022
?>
A common use case seen across several industries is the creation of systems capable of detecting the similarity between pairs of objects – images and texts. For example, duplicate detection in marketplaces, or recommendation systems that show similar objects to the ones the user has searched for, can use such systems. They can also be useful for detecting plagiarism in a thesis or articles due to the massive number of publications over the years. So, being text so a widespread data modality, being able to do duplicate detection in text is a critical task in Machine Learning.
But how can we make these systems? A human can easily perceive the similarity between two sentences said differently. For example, the sentences “She survived” and “She did not die” have the same meaning. A text similarity algorithm is expected to retrieve a very high similarity rate. To do this, Machine Learning is the right path, but it’s not that easy, due to the complexities of Natural Language Processing (NLP).
This article describes the creation of two tools I developed with the orientation of Pedro Dias, a Data Scientist at NILG.AI, for my curricular internship.
Natural Language Processing and text modeling
NLP is a subfield of artificial intelligence concerned with the interactions between computers and human language, particularly how to program computers to process and analyze large amounts of natural language data.
Text modeling was the main base of my work. It consists of analyzing text data to find a group of words from a collection of documents that best represents the information in the collection.
Of course, there are many ways to perform feature extraction from texts, but the path chosen was to use Word2vec and bag-of-N-gram.
Word2Vec is a method to obtain word embedding, a term used to represent words in a vector space for text analysis. Once trained, it can detect synonymous words or suggest additional words for a partial sentence.
Bag-of-N-gram is a technique that counts how many times an N-gram appears in a document. An N-gram is a sequence of N words where N is a number between 1 and infinite. For example, given the sentence “Hello neighbor next door,” “Hello World” / “next door” is a 2-gram while “Hello neighbor next door” is a 4-gram.
Duplicate Detection in Text Using Machine Learning
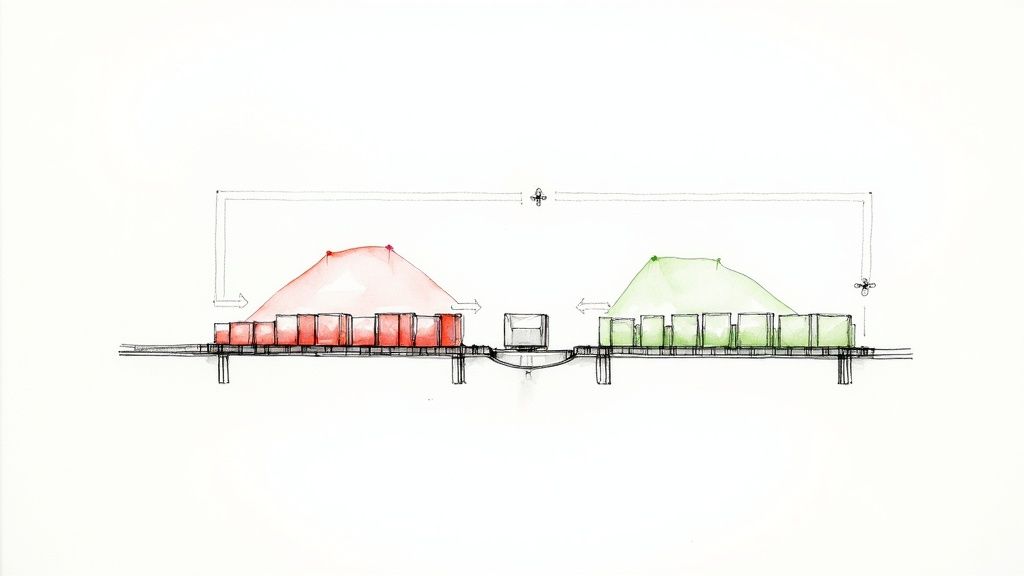
One of the tools created had the objective of retrieving the similarity between two texts inserted by the user. To do that, an abstract representation of these texts was created with different methods. The next step was calculating the distance between these abstract representations, generating the probability of being similar. Below is a scheme to better understand these steps.
The other tool created allowed the user to enter a text, and it returned the most 10 similar texts from a bank of texts. This bank of texts belongs to a dataset from Quora Question Pairs.
There were three types of approaches in the development of the product: an unsupervised, using Word2Vec and Bag-of-N-gram for the abstract representation, a supervised, using Logistic Regression, and another that simulates real-life situations explained further on.
All of these methods used the dataset mentioned above, and represented in the figure below, to train the model.
Real-life simulation
In this approach, the initial dataset has a particularity. The second question is replaced by a synonymous phrase, but only the rows that indicate that the questions are duplicates. This simulates the case where two phrases with different but similar words have the same meaning, and a scenario where there is no annotated data for the duplicates, but we can still train a model.
Development of a Rest API and a Web App
Furthermore, two services were created to make the tool that can retrieve the similarity between two texts, and the one that, given a text, returns the most similar texts from a bank of texts. These services were implemented for every method. Integrating these models in a Rest API (backend) and a Dash Interface (frontend), you can find the final result in this dashboard.
Automation of deployment
This was made to release the versions without much effort and a much more seamless way of delivering products in the industry. To put the above-mentioned services into production using Terraform, an EC2 machine, and an ECR repository were created to store the docker images of each interface.
By generating the docker image on a computer and pushing them to the ECR repository, it is only needed to access the machine-generated EC2 instance and pulling these images from the ECR repository. The image below intends to clarify this process further.
These steps are all aggregated in a deployment script to make the release easier for a possible client.
Conclusions on my internship: Duplicate detection in text data
I believe that the work on duplicate detection in text was carried out successfully, although I consider that I could increase the accuracy and reliability of the tools created with more time.
This experience allowed me to be part of a project that has a lot of use for companies or private entities, such as detecting duplicate data to delete it, or detecting plagiarism.
Overall, I felt that it was an internship that put me more in touch with the business world and gave me a lot of knowledge in the machine learning area, especially about NLP and supervised and unsupervised learning. It also gave me more knowledge about how to make a deployment, not only focusing on the artificial intelligence area.
Ultimately, I would like to thank my excellent tutor from NILG.AI, who was always willing to help and teach me throughout the semester.
Like this story?
Subscribe to Our Newsletter
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
Managing Operational Risk: Proven Strategies & Best Practices
Jun 30, 2025 in
Industry Overview
Learn effective methods for managing operational risk. Discover key frameworks, controls, and culture tips to protect your business today.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.