What do you do when the model is underperforming? When the models’ performance does not meet our expectations, we usually spend time searching for the flaws, selecting and analyzing the cases where it failed to understand why it happened. Then, we try to apply more robust solutions, train, test, and repeat. In some cases, we succeed but in others, the model’s performance does not increase, no matter how hard we try.
What to do? The temptation to give up increases with the number of failed attempts. Since trying to fix the model’s defects didn’t lead to success, what about doing the opposite? Try to focus on the cases where your model succeeds. Select those cases, analyze them, and measure the value they contain. Do not toss your model into the garbage bin because it is missing some cases. Instead, take advantage when it gets them right!
The Solution
First of all, analyze your predictions! When the model is underperforming, the predictions might be distributed in two ways:
Completely random: no matter the range of scores you are selecting, the percentage of positives and negatives is similar to the global population. When this happens, the model didn’t learn anything and you need to rethink the learning strategy.
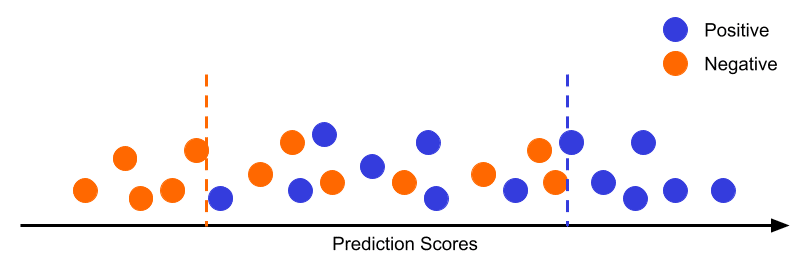
Accurate at the tails and random at the center: This is the most common case. Sometimes, the model is able to predict correctly the instances that are strong positives or strong negatives but it fails on categorizing the instances that have features correlated with both classes. I.e. the model struggles to find a good boundary between classes. If that’s the case, here is the solution: instead of defining a single boundary, define 2, one for the positive tail and another for the negative tail; if the prediction score is under the negative boundary or over the positive boundary, leave it with the model, otherwise, add a human in the loop and pass it to them.
The tails analysis should focus on two main factors:
the performance of the model on the tails – extract the visualization of the Sidekick KPI over the inclusion rate (the inclusion rate decreases when the positive and negative boundaries are pushed to the extremes)
the opportunity size on the tails – extract the visualization of the Hero KPI over the inclusion rate.
Course, Templates
Data Ignite
If Hero and Sidekick KPIs are new concepts to you, check our Data Ignite Course.
The viability of this approach depends on how you are going to integrate AI into your business. Integration of the type filtering, where the AI is used to reduce the workload that is passed to a human, any inclusion rate higher than 0% can be profitable. However, an integration of the type replacing, where the aim is to replace an existing process with an AI system, might require a higher inclusion rate to become profitable. But, when can we use it in practice?
In Healthcare, most of the Use Cases of diagnosis support are of the type filtering. Making an autonomous AI system for disease diagnosis can be very challenging or even unrealistic since in a lot of cases specialists’ opinions are not unanimous. With filtering the AI is able to screen a small segment of patients, but with high confidence in the decision, while the remaining patients are forwarded to a doctor.
Hot and cold leads are a type of use case where the hottest and coldest leads are identified to further play action on those leads or on the remaining. For example, if you are too sure that a segment of leads is going to churn, no matter what, you might avoid investing in customer service on those leads/clients. On the other hand, if you’re too sure that a lead is going to convert, you don’t need to invest more resources to convince them, or you could already think of a strategy to upsell other products. Since these use cases depend on segment identification, identifying the tails is a useful and profitable strategy.
Recommendation Systems are another type of use case that can benefit from this approach. Usually, the models have a good performance when they have a history of the client but they tend to fail on new customers, without action history – cold start. When this happens, select the customer segment for which the model has a good performance and start there.
If you think this solution is not profitable enough for your business, don’t think of it as the end of the road but as the road itself. After selecting the segment where your AI is reliable, you can put the solution into production and use the cash flow it is returning to invest in data acquisition, data labeling, and deeper model exploration. This way, you’ll need an initial investment to create a simple solution and the remaining investigation process can be supported by itself.
So, keep in mind:
Bad models don’t have to be useless models – explore their potential before flushing all the work you invested in them
Hero KPIs are much better indicators than sidekick KPIs
If it’s still not a good end, see it as the means.
Like this story?
Subscribe to Our Newsletter
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
Unlock Growth with Customer Lifetime Value Prediction
Jul 13, 2026 in
Guide: Explainer
Unlock real growth with customer lifetime value prediction. Learn key models, data needs, & implementation roadmaps for strategic results.
A Strategic Guide to Generative AI for Business Transformation
Jul 1, 2026 in
Guide: Explainer
Unlock real growth with our guide to generative AI for business transformation. Learn to build a roadmap, find high-value use cases, and measure your AI ROI.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.