Text classification is one of the most common use cases in Natural Language Processing, with numerous practical applications – now easier to access with Large Language Models. Companies use text classification in multiple scenarios to become more efficient:
Tagging large volumes of data: reducing manual labor with better filtering, automatically organizing large volumes of text.
Enhancing Search/Recommendation Systems: Search and recommendation can be enhanced by a better understanding of the searched queries.
Sentiment Analysis: Understanding public opinion/customer feedback by determining the emotion expressed in text is valuable for.
Customer Support: Facilitate ticket prioritization and routing to the correct team by categorizing customer support tickets.
All of these use cases were solvable in the past without using LLMs. However, the uprising of these models has reduced the amount of necessary training data for obtaining good results, and has also increased the average performance of these use cases, taking less time for reaching them!
In this blog post, we will cover several techniques for text classification before the uprising of the most recent LLMs (OpenAI, LLaMA, Bing, …) and after.
FREE eBook: How to transform your business with AI
Download our eBook and discover the most common pitfalls when implementing AI projects and how to prevent them.
Most common techniques for Text Classification using Large Language Models
The most common techniques for text classification are:
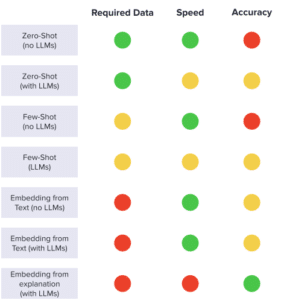
Zero-Shot Classification: asking a model for a label directly, without giving any examples. Although it’s the simplest option, and you don’t need any data, performance is quite limited, and you can end-up with an outcome that is not a part of your fixed class list (hallucination).
Post-LLMs: Directly requesting LLMs to generate a label, passing a final structure. This approach is slower than pre-LLMs: although much more accurate.
Few-Shot Classification: you pass a few examples per class, and require a low amount of annotated data.
Pre-LLMs: Using open-source models such as TARS
Post-LLMs: Using LLMs by passing in the prompt’s context the samples of each class. Will be more accurate than the previous approach.
Raw embedding feature extraction: we convert the text into a numerical representation (embedding) and train a model on top of that, which retrieves a probability score that can be used for making decisions. However, you require a larger amount of annotated data.
Pre-LLMs: Using open-source embeddings such as GloVE.
Post-LLMs: Using OpenAI embeddings, which are trained on larger amounts of data and typically outperform other embedding methods. This is a paid option, of which you need to consider the trade-offs compared to using an open source solution.
Embeddings of enriched text: Before extracting the embeddings, we try to uncover more information about the text, “enriching it”.
Pre-LLMs: Not frequently used.
Post-LLMs: ask the LLM to give you more information about the text: for example, if it’s a Google Search, LLMs can give you more information about what that search encompasses. It’s a slower approach than Pre-LLMs, but it’s the technique with the highest scores we’ve seen so far.
“Let’s assume you’re an Encyclopedia, and you have to define the concepts I’m providing. Your explanation must be succinct (couple of paragraphs), like the summary section of a Wikipedia article talking about the concept. (…)”
Below is a comparative chart, summarizing the trade-offs of the methods in terms of required data, speed and accuracy.
Conclusion
We showed you several ways of doing text classification using Large Language Models. LLMs allow you to reach acceptable performance in a few hours of work and are pretty good for an initial benchmark – despite this, don’t forget about older methods, which can be a fallback when you want faster outcomes or when paying for LLMs’ requests is not feasible in the scale of your use case.
Want to revolutionize the way you do text classification? Know more by contacting us!
A Strategic Guide to Generative AI for Business Transformation
Jul 1, 2026 in
Guide: Explainer
Unlock real growth with our guide to generative AI for business transformation. Learn to build a roadmap, find high-value use cases, and measure your AI ROI.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.