AI Strategy • AI4business • AI4tech • Data Scientist • Management •
A Guide to Data Science Project Management
NILG.AI on Jul 29, 2025
?>
Trying to manage a data science project with a traditional project management playbook is a recipe for disaster. It’s like trying to navigate a new continent with a street map of your hometown—the tools just don’t match the territory. The core of the problem is that data science is all about exploration and discovery, not building something with a fixed blueprint.
Why Traditional Project Management Fails Data Science
Let’s get one thing straight: running a data science project is fundamentally different from a typical software development cycle. The path is rarely linear, and the final destination can change based on what you find in the data. Old-school methods, especially rigid ones like the Waterfall model, just fall apart because they’re built on the assumption of predictable steps and a clearly defined final product.
Think about building a house. You have detailed blueprints, a list of materials, and a pretty solid timeline. You don’t get the framing up and then suddenly decide you’re building a skyscraper instead. But in data science? That kind of pivot happens all the time. An initial hypothesis might turn out to be a dead end, or the data might reveal a completely different, more valuable problem to solve.
The real disconnect is that traditional methods are designed to manage the completion of tasks. Data science project management, on the other hand, is about guiding a process of discovery and learning. The goal isn’t just to deliver a product; it’s to uncover an insight or build a capability that you might not have fully understood at the outset.
To really get a feel for this, let’s look at how these two worlds differ side-by-side.
Traditional vs Data Science Project Management
Aspect
Traditional Project Management
Data Science Project Management
Primary Goal
Deliver a predefined product or feature.
Answer a business question or discover insights.
Process
Linear and sequential (e.g., Waterfall).
Iterative and experimental (e.g., CRISP-DM, Agile).
Requirements
Fixed and defined upfront.
Evolve as data is explored and understood.
Outcome
Predictable. A working piece of software.
Uncertain. An insight, a model, or a recommendation.
Key Metric
On-time, on-budget delivery.
Value of the insight, model accuracy, business impact.
Risk
Scope creep, budget overruns, technical debt.
Useless findings, poor data quality, unachievable goals.
As the table shows, we’re dealing with two completely different beasts. One is about execution and efficiency, while the other is about research and value creation under uncertainty.
The Unpredictable Nature of Data Science Work
At its heart, data science is one big experiment. You start with a question, not a guaranteed answer. This built-in uncertainty throws a wrench into any rigid framework.
Here’s where things get messy:
Ambiguous Outcomes: You might kick off a project to predict customer churn, only to find that the real gold is in identifying specific customer segments you can proactively save with a targeted campaign. The deliverable itself changes.
Constant Experimentation: Data scientists live in a loop of testing different models, tweaking features, and trying new algorithms. This cycle of building, testing, and learning is the job—it doesn’t fit into neat two-week sprints designed for shipping user stories.
Data-Driven Direction: The data is the real boss here. A surprising discovery or a major data quality issue can send the project in a completely new direction. For a traditional project manager, that’s a nightmare. For a data science team, it’s just Tuesday.
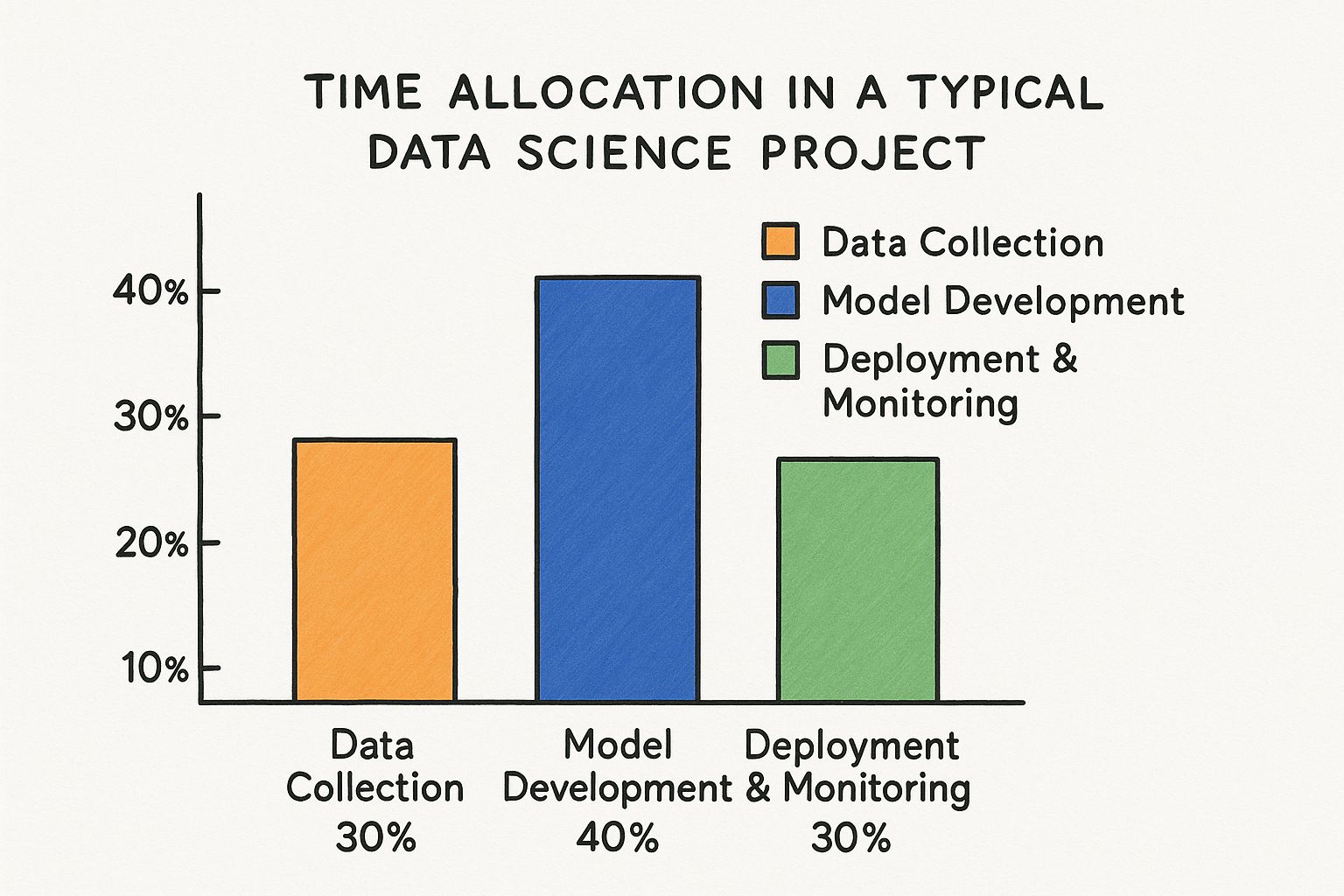
This chart really drives the point home, showing where a data scientist’s time goes. The bulk of it is spent on the highly iterative and unpredictable task of model development.
What this visual screams is that the most time-consuming part of the project is also the least predictable. You can’t just schedule “innovation” from 9 to 5.
A New Mindset for a New Discipline
To succeed, you have to stop fighting the chaos and start embracing it. We need to shift from rigid Gantt charts to flexible, adaptable frameworks. The messiness isn’t a bug; it’s a feature of the discovery process. This means prioritizing rapid iteration, open communication about what we don’t know, and flexibility.
The industry is catching on. The complexity of these projects is driving a huge demand for better tools. The project management software market, valued at an estimated $7.24 billion in 2025, is expected to jump to $12.02 billion by 2030. With 82% of companies already using some form of this software, it’s obvious that having the right platform is critical. You can discover more insights about project management trends on monday.com to see how the landscape is shifting.
Ultimately, great data science project management isn’t about cramming a research process into a construction schedule. It’s about building a system that nurtures exploration, adapts to new information on the fly, and keeps everyone on the same page—even when the final destination is still a fuzzy dot on the horizon.
Laying the Groundwork for Project Success
Before anyone even thinks about writing code or loading up a dataset, the real work on any data science project has to happen. This is all about building a solid foundation. I’ve seen it time and time again: teams that rush this part end up with a technically brilliant model that solves the completely wrong problem.
The whole point here is to get past those vague business requests and hammer out a clear, actionable plan. This isn’t just about filling out forms; it’s the strategic thinking that separates a successful project from a costly science experiment that goes nowhere.
From Vague Questions to Testable Hypotheses
Let’s be honest, stakeholders often come to the data science team with broad goals like “let’s reduce customer churn” or “we need to improve sales.” These are fine starting points, but you can’t build a project on them. The first real step in data science project management is to translate those big ideas into something you can actually test.
Here’s the difference:
Weak goal: “We want to use AI to improve marketing.”
Strong hypothesis: “We believe that by building a model to identify customers at high risk of churning in the next 30 days, we can target them with a specific retention offer and cut our overall churn rate by 5%.”
Making this shift does two crucial things. First, it gives the data team a clear target to aim for. Second, it creates a measurable definition of success that everyone on the business side can understand and get behind.
A well-formed hypothesis is your project’s North Star. It guides every decision you make, from which data to pull to the model you choose, ensuring your technical work stays locked onto a real business outcome.
Master the Art of Data Discovery
Okay, so you have a solid hypothesis. Now what? The next step is a crucial reality check: do you even have the ingredients to test it? This is the data discovery phase. So many projects fall apart weeks or months down the line simply because the team finally realizes the data they need is messy, missing, or just doesn’t exist.
Your initial dig into the data should answer a few key questions:
Is it there? To build a churn model, you need historical customer behavior, subscription details, support tickets, and so on. Do you actually collect that?
Is it any good? Missing values, typos, and weird formatting can completely derail a project before it even gets going.
Is it relevant? Does the data actually have signals that could predict what you want? A quick analysis might show you’re missing the key behavioral data that truly correlates with churn.
This is also the point where you need to start thinking about the underlying tech. A solid plan for your infrastructure is non-negotiable; the right setup can make or break your ability to scale later on. If you want to dive deeper into building a solid technical backbone, check out our guide on data science architecture here: https://nilg.ai/202505/data-science-architecture/
Defining Success Beyond Model Accuracy
A model with 99% accuracy is totally useless if it doesn’t create any business value. Defining your success metrics is one of the most important things you’ll do at the start. These metrics have to connect directly to the business goal, not just the technical performance of the model.
Think about it this way:
Technical Metric: Our model has an F1-score of 0.85.
Business Metric: We saw a 15% lift in conversions from the marketing campaigns targeting the segments our model identified.
Or another example:
Technical Metric: We achieved a low Root Mean Squared Error (RMSE) in our sales forecast.
Business Metric: We cut inventory overstock costs by 10% because the forecast was so much better.
Of course, a huge piece of this foundational work is getting the right people on board. Your project’s success depends entirely on having skilled pros who can build, deploy, and maintain these complex systems. That means figuring out your strategy for hiring data scientists and AI/ML engineers. The right team is just as critical as the right problem.
By setting these business-focused KPIs from the very beginning, you make sure everyone—from the data scientists in the trenches to the execs in the C-suite—is on the same page about what “done” and “successful” actually look like. This makes the whole data science project management process run a lot smoother.
Navigating the Iterative Execution Loop
Alright, this is where the theory hits the fan. Your beautiful project plan now has to survive contact with real, messy data. The execution phase in a data science project isn’t some straight, predictable path. It’s a cyclical, often chaotic loop of exploring, modeling, and evaluating. Your main job here is to manage this cycle without letting your team get lost in endless, aimless experiments.
Forget about planning every single step for the next six months. It’s a waste of time. The real secret is to break down the work into short, focused bursts—think sprints, but with a research-oriented twist. Instead of building product features, you’re tackling specific research questions. This agile approach gives you the flexibility to pivot quickly when the data inevitably throws you a curveball.
For example, a sprint might be designed to answer a single question: “Can we find any real connection between how users engage with our website and the value of their first purchase?” At the end of that sprint, you don’t need a perfect, finished model. You just need a clear “yes,” “no,” or “maybe, but we need more data.” That answer then dictates what you do in the next sprint.
Structuring Sprints Around Research Questions
The standard agile playbook for software development needs a few tweaks here. You aren’t just burning through a backlog of user stories; you’re methodically chipping away at a mountain of uncertainty. Each cycle should build directly on what you learned in the last one, creating a trail of evidence that either proves or disproves your project’s main hypothesis.
Let’s imagine you’re building a new product recommendation engine. Your sprints could look something like this:
Sprint 1: Can we even get our hands on the user interaction data and clean it up? Is there enough variety in it to be useful?
Sprint 2: What’s the simplest model we can build to set a baseline? How well (or poorly) does it perform?
Sprint 3: Can we make it better by adding user demographic data? Does doing so introduce any weird biases?
Sprint 4: Let’s test a more complicated algorithm. Is the tiny performance boost actually worth the extra complexity and cost?
This method makes your progress real and tangible. Even when an experiment “fails,” it’s a win because it gives you valuable information and stops the team from chasing a dead end for weeks.
One of the most important mindsets to adopt is treating every outcome as a learning opportunity. A model that flops isn’t a failure; it’s a crucial finding that points you toward a more promising path. This simple reframe is a game-changer for team morale and stakeholder conversations.
The Non-Negotiables: Documentation and Versioning
When you’re moving this fast, it’s dangerously easy to lose track of what you’ve already tried. Meticulous documentation isn’t just a “nice-to-have” bureaucratic task; it’s the lifeline that ensures your work is reproducible and keeps everyone sane. Your team absolutely has to track their experiments, version their models, and manage their data features.
Picture this: two months into the project, a key stakeholder asks why you abandoned a specific approach. With a solid experiment log, you can pull up the data-backed answer in minutes. Without it, you’re just relying on someone’s fuzzy memory, which is a perfect recipe for repeating mistakes and causing chaos.
On a larger scale, managing these iterative projects falls under the umbrella of project portfolio management (PPM). This high-level view ensures that what your team is doing day-to-day actually aligns with the company’s bigger goals. There’s a reason the global PPM market was valued at around $6.13 billion in 2024 and is projected to grow at 13.0% each year through 2030. In fact, about 80% of project managers believe it’s essential for business success. If you’re curious, you can find more project management statistics at PM360 Consulting to see how these trends are shaping the industry.
Communicating Progress When The Path Is Squiggly
Talking to stakeholders during this phase is a true art form. They’re often used to seeing neat, linear progress on a Gantt chart, but your progress looks more like a winding, exploratory trail. The trick is to communicate what you’re learning, not just what you’re building.
So, instead of saying, “We haven’t built the final model yet,” try this: “This week, we confirmed that customer location data isn’t a predictive signal, which saves us from building out a complex and useless feature. Our initial analysis shows purchase history is far more promising, so we’re diving into that next.”
This kind of communication frames the team as strategic problem-solvers, not just code monkeys ticking off tasks. This proactive approach to data science project management builds incredible trust and keeps everyone on the same page, even when the final destination isn’t yet in sight.
From Model to Market: Deployment and Real-World Value
Let’s be blunt: a brilliant model that never leaves a data scientist’s laptop is just a very expensive, very clever hobby. It’s completely worthless to the business. This final stage is all about getting your work off the bench and into the real world—the messy, unpredictable place where it can finally start making a difference.
This is often the hardest part of data science project management. It’s packed with its own unique technical and organizational headaches. Getting a model into production almost always comes down to solid system integrations with your existing tech stack. This is where the theory ends and the real work begins. Your model has to talk to your other systems, whether that’s a CRM, a marketing platform, or an inventory tool, pulling in live data and pushing out predictions without a hitch.
From Notebook to Production Pipeline
The code that works perfectly in a neat and tidy Jupyter notebook is almost never ready for the chaos of production. It’s a different beast entirely. You suddenly have to worry about things like scale, speed, and what happens when things inevitably break.
Can the model handle thousands of requests a second? Will it spit out a prediction fast enough to be useful? What’s the backup plan if it crashes at 3 AM?
Building a robust deployment pipeline isn’t optional. This usually involves a few key steps:
Containerization: We package the model and all its dependencies into a container (using something like Docker). This is like putting it in a self-contained box, ensuring it runs the same way everywhere.
API Creation: We build an API (Application Programming Interface) around the model. Think of this as creating a simple, universal remote control so other applications can easily use it.
Infrastructure Setup: We have to decide where this model will live. Will it be on our own servers, or in the cloud using a service like AWS SageMaker or Google AI Platform?
This is a team sport. Your data scientists, ML engineers, and IT ops folks have to be in constant communication. One small misunderstanding here can create massive headaches and technical debt that will haunt you for months.
The goal isn’t just to flick a switch and make the model “live.” You’re building an automated, reliable, and scalable system that runs on its own. It’s less like building a custom tool and more like building a small, automated factory.
Monitoring Performance and Catching Model Drift
Once your model is out in the wild, you can’t just walk away. A whole new job begins: monitoring. Models aren’t static things; their performance naturally decays over time in a process we call model drift. This happens when the live data flowing into the model starts to look different from the data it was trained on.
For example, imagine a model trained to predict customer churn right before a global pandemic. A few months later, customer behavior has changed so dramatically that the model’s predictions are now wildly off-base. Without monitoring, this can go unnoticed for months, leading to terrible business decisions and destroying any trust the company had in your team’s work.
A good monitoring strategy keeps an eye on two things:
Monitoring Type
What It Tracks
Example Question It Answers
Data Drift
The statistical profile of the input data.
Are we suddenly getting user data from a new country the model has never seen before?
Concept Drift
The relationship between inputs and outputs.
Is the link between a customer’s browsing habits and their likelihood to buy something weaker than it was last month?
You absolutely need automated alerts for these drifts. When an alert fires, it should kick off a process to figure out what’s wrong, which usually means it’s time to retrain the model with fresh data and redeploy it.
The Hand-off, Documentation, and Adoption
Finally, you need to make sure people actually use what you’ve built. This means a clear hand-off to the teams who will rely on the model every day. Good documentation is your best friend here. And I don’t just mean technical specs. It needs to explain in plain English what the model does, what its limits are, and how to make sense of its outputs.
This is the last mile, and it’s where you secure the return on your investment. A successful deployment isn’t just a technical win; it’s an organizational one. It’s about making sure all that hard work gets adopted, integrated, and keeps delivering real value long after the project officially wraps up.
Using AI to Manage Your AI Projects
It’s a little ironic, isn’t it? We spend our days building sophisticated AI systems, but when it comes to managing the projects themselves, we often fall back on old-school spreadsheets and gut feelings. It’s time we started eating our own dog food, so to speak.
The good news is, we can. By applying AI to our own data science project management workflows, we can make the entire process smarter, faster, and far more predictive. This isn’t some pie-in-the-sky idea; it’s about using practical tools available right now to get ahead of problems before they completely derail a project.
Get Ahead of Risks and Nail Your Timelines
One of the biggest game-changers here is predictive analytics. Instead of just reacting when things go wrong, you can start seeing trouble coming from a mile away. AI tools can chew through historical project data, look at team availability, and analyze current progress to flag potential bottlenecks before they ever happen.
Picture this: your AI notices that any project touching a specific legacy database tends to run 15% over schedule. The moment you kick off a new project with that same dependency, it flags the risk. Now you can build in a buffer or assign extra help from the get-go.
That’s a monumental shift from reactive firefighting to proactive, strategic management.
Let AI Handle the Tedious Stuff
Think about how much of a project manager’s day is eaten up by grunt work. Chasing status updates, compiling reports, nudging people about deadlines—it’s all necessary but incredibly draining. This is precisely the kind of low-hanging fruit AI automation was made for.
Imagine a system that automatically:
Pulls data from Git and your task board to generate weekly progress reports without you lifting a finger.
Summarizes meeting transcripts into clear action items and key decisions, so no one has to be the designated note-taker.
Sends smart reminders to team members based on their actual progress, not just a blind calendar alert.
The whole point is to free up your experts—both managers and data scientists—to focus on the creative, complex problem-solving you hired them for. Let the machines handle the administrative grind.
Make Smarter Resource Decisions
Assigning the right person to the right task has always been more of an art than a science. AI can bring a lot more data to that art form. It can analyze a team member’s past performance, their specific skills, and even their current workload to suggest the best fit for a new task.
For example, an AI tool could see that one of your data scientists crushes natural language processing tasks and is about to free up. It would then flag them as the perfect person for that upcoming sentiment analysis project. This turns resource planning from a simple availability check into a truly strategic, skills-based decision.
This isn’t just a niche trend; it’s the direction the entire industry is heading. A recent study found that 82% of senior leaders plan to integrate AI into their projects within five years. And as of 2023, 21% of project managers were already using AI tools to help with project execution. You can check out more stats and what they mean for management roles in this detailed statistical report.
Ultimately, bringing AI into your management process is about making the entire project lifecycle more intelligent. And when you have a structured approach to your projects, the benefits are even greater. For a deeper dive into organizing complex initiatives, take a look at our article on whether https://nilg.ai/202405/can-the-star-framework-streamline-your-ai-projects/. It all ties back to the same goal: building better data science outcomes, more successfully.
A Few Common Questions About Data Science Projects
Even when you have a great framework, data science project management is full of unique curveballs. This field is a weird mix of research, engineering, and business strategy, so it’s only natural for questions to pop up. Let’s dig into some of the most common ones I hear and get you some clear answers you can actually use.
Why Do So Many Data Science Projects Fail?
Ah, the elephant in the room. It’s true, a ton of data science initiatives just don’t deliver on their promise. But here’s the thing: it’s rarely a technical failure. Most of the time, projects go completely off the rails for business and process reasons, long before anyone even starts building a model.
The biggest culprit? A total disconnect from real business value. A project will kick off with a fuzzy goal like, “we need to use AI,” but there’s no clear, measurable problem to solve. This leads to these technically impressive solutions that don’t actually move the needle for the company. The team builds a brilliant model, but nobody knows what to do with it.
Another huge problem is terrible data quality or access. Teams often find out way too late that the data they need is a complete mess, full of gaps, or locked away in some ancient, siloed system. What started as a data science project quickly turns into a data engineering nightmare, burning through time and budget with almost nothing to show for it.
One of the most common traps I see is when teams mistake a research project for a product development project. They deliver a fascinating analysis or a model with high accuracy, but there’s no plan to actually put it into production. The project is technically a “success,” but its business impact is zero.
Finally, a lack of buy-in and communication can be a project killer. If the business folks don’t get what the data team is doing or why it’s important, they won’t fight for it when budgets get tight or priorities inevitably shift.
Agile for Data Science vs. Agile for Software: What’s the Real Difference?
So many teams try to copy-paste the Agile Scrum framework from their software development colleagues directly onto data science work, and it’s almost always a mess. While both fields benefit from an iterative mindset, what they’re trying to achieve is fundamentally different, and that calls for a different playbook.
Agile for software is all about delivering working features. Sprints are designed to produce tangible bits of a product that a user can see and touch. The work is relatively predictable—you know what you’re building, and the main risk is just in getting it done.
Data science Agile, on the other hand, is all about reducing uncertainty through experimentation. The goal of a sprint isn’t always to ship a feature; it might be just to answer a research question. The output could be a key finding, a validated hypothesis, or even a failed experiment that importantly tells you what not to do next.
Here’s how I think about the practical differences:
Aspect
Agile for Software Development
Agile for Data Science
Sprint Goal
Build and ship a functional piece of software.
Answer a research question or test a hypothesis.
Backlog Items
User stories with clear acceptance criteria.
Research questions, experiments, data tasks.
Definition of “Done”
The feature is coded, tested, and shippable.
The experiment is finished, and we have a clear takeaway.
Predictability
High. Velocity is a reliable metric for planning.
Low. You can’t schedule breakthroughs.
This distinction is everything. Trying to cram exploratory data science into rigid, feature-factory sprints just leads to frustration. The real key is to adapt the principles of agile—iteration, feedback, collaboration—to a research context. This might mean using frameworks like CRISP-DM or a modified version of Scrum. Often, the insights from these projects can spark bigger ideas; in fact, you can find many great business process automation examples that started out as simple data science explorations.
What Are the Essential Tools for a Data Science Team?
Look, tools don’t make the team, but having the right stack is absolutely critical for keeping things efficient and collaborative. A modern data science toolkit really breaks down into a few key areas.
First up, a central place for code and version control. This is completely non-negotiable.
Git: It’s the undisputed standard for a reason. Everyone uses it.
GitHub/GitLab/Bitbucket: These platforms are where your Git repositories live. They add crucial collaboration tools like pull requests, issue tracking, and code reviews on top.
Next, you need a solid environment for experimentation and development.
Jupyter Notebooks: This is the playground for data scientists. It’s the go-to for interactive exploration, quick visualizations, and prototyping ideas. Most of the team will live here day-to-day.
Integrated Development Environments (IDEs): When it’s time to write production-level code, you need a real IDE like VS Code or PyCharm. They bring essential features like debugging and smart code completion.
Finally, you need tools for project and workflow management. This is where you bring order to the chaos.
Project Management Platforms: Tools like Jira, Asana, or Trello, when you customize them for a data science flow, are great for tracking tasks, managing backlogs, and giving everyone visibility.
MLOps Platforms: Tools like MLflow, Kubeflow, or Weights & Biases are becoming indispensable. They help you track experiments, manage models, and deploy them reliably, bringing some much-needed engineering discipline to the science.
A good toolkit supports the entire journey, from that first spark of an idea in a notebook all the way to a version-controlled model humming along in a production environment.
At NILG.AI, we specialize in transforming business challenges into growth opportunities with clear, effective AI strategies. From process automation to predictive analytics, we provide the expertise and tools to help your team succeed. Discover how we can help you build a data-driven future: Request a proposal
Like this story?
Subscribe to Our Newsletter
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
Digital business transformation examples: 10 Real-World Case Studies
Feb 10, 2026 in
Listicle: Examples
Discover digital business transformation examples and how AI, data, and strategy fuel growth with practical, actionable insights.
Master customer retention rate calculation with this practical guide. Learn the formulas, see real-world examples, and get actionable tips for business growth.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.