How to Build Predictive Models That Drive Business Growth
NILG.AI on Oct 14, 2025
?>
Building a predictive model isn’t just a technical exercise; it’s a strategic business process. It all starts with a crystal-clear business goal, moves into gathering and whipping your data into shape, picking the right algorithm for the job, and then training, testing, and finally deploying your model where it can do some real work. The whole point is to solve a real problem, not just to build a cool piece of tech.
Start with Business Problems, Not Algorithms
I’ve seen it a hundred times: a team gets excited about a new machine learning algorithm and immediately tries to find a place to use it. This is completely backward. The most powerful, technically brilliant model is a total waste of time if it doesn’t solve a genuine business challenge.
So, before you even think about code, you need to frame the objective. What are you really trying to accomplish? The answer must be a business outcome. Don’t say, “I want to build a classification model.” Instead, aim for something like, “We need to cut customer churn by 15% in the next quarter.” This business-centric AI approach is what ties your work directly to the bottom line.
Predictive models are great for tackling all sorts of common business headaches:
Customer Churn: Who’s about to walk out the door in the next 30 days?
Inventory Forecasting: How many widgets will we sell in the Midwest next month?
Predictive Maintenance: Which of our factory machines is on the verge of breaking down this week?
Lead Scoring: Is this new lead a hot prospect or just kicking the tires?
The Critical Foundation: Data Preparation
Once you’ve nailed down your business goal, it’s time to shift gears to the most important phase of the entire project: data preparation. This is way more than just cleaning up a messy spreadsheet. It’s about strategically finding the right information, putting it through rigorous quality control, and sniffing out any hidden biases that could completely poison your results.
Seriously, getting the data right can account for up to 80% of a machine learning project’s success. Just look at the finance industry, where companies use pristine datasets to nail fraud detection with over 90% accuracy, saving themselves millions.
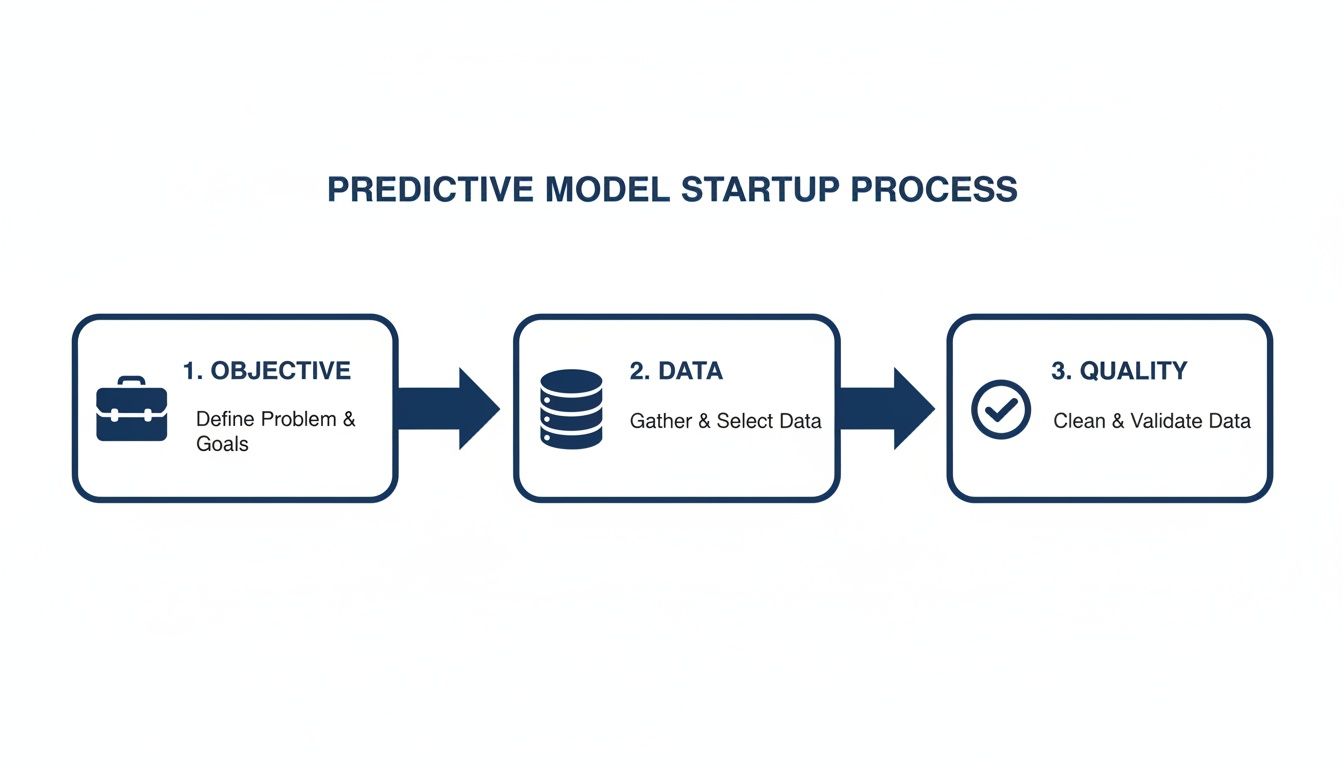
This whole process follows a logical flow. You start with the objective, then dive deep into the data and its quality.
As you can see, a solid business objective and high-quality data aren’t just nice-to-haves; they are the absolute foundation of any successful model.
The old saying “garbage in, garbage out” is the gospel truth in predictive analytics. Your model is only ever as smart as the data it learns from. Spending the extra time here will save you from massive headaches down the road.
Identifying and Addressing Data Quality Issues
Bad data can be subtle but absolutely devastating. Let’s say you’re building a churn model, but your dataset only tracks customer activity from the last six months. You’d completely miss the behavior patterns of your most loyal, long-term customers, and your predictions would be wildly off.
Hidden bias is another killer. If your historical loan data shows that a certain demographic was consistently rejected (fairly or not), a model trained on that data will just learn to automate that same bias. It’s a huge risk.
To dodge these bullets, you have to grill your data during the quality check phase:
Is this data even relevant to the problem I’m trying to solve?
Are there huge gaps or a ton of missing values?
Does this data reflect historical biases that we don’t want to repeat?
Is this dataset big enough and varied enough to actually represent the real world?
Answering these questions early on builds a rock-solid foundation. It’s what separates the models that actually drive ROI from the ones that end up as nothing more than interesting but useless science experiments.
To give you a bird’s-eye view, the entire modeling process can be broken down into a few core stages. Each one has a specific goal and a set of activities to get you there.
Key Stages of the Predictive Modeling Lifecycle
Stage
Primary Goal
Key Activities
Problem Framing
Define a clear, measurable business objective.
Stakeholder interviews, ROI estimation, KPI definition.
Data Collection
Gather all relevant data from various sources.
Database queries, API integration, data sourcing.
Data Preparation
Clean, transform, and structure the data.
Handling missing values, outlier detection, data normalization.
Feature Engineering
Create meaningful predictive variables.
Creating new features from existing data, selecting the most impactful features.
Model Training
Teach the algorithm to find patterns in the data.
Algorithm selection, hyperparameter tuning, training on historical data.
Model Evaluation
Assess the model’s performance and accuracy.
Cross-validation, testing with unseen data, checking against business KPIs.
Deployment & MLOps
Integrate the model into a live business process.
API development, setting up CI/CD pipelines, containerization.
Monitoring
Ensure the model continues to perform well over time.
Tracking model drift, performance degradation alerts, retraining schedules.
This lifecycle view helps keep the project on track, ensuring you don’t skip crucial steps on the way to a valuable, real-world solution.
Choosing the Right Tools for the Job
Alright, you’ve framed your business problem and your data is looking clean. Now for the fun part: picking your algorithm. The world of machine learning is packed with options, but this isn’t about grabbing the shiniest new tool. It’s about finding the perfect fit for the job at hand.
For a lot of folks, this is where things can get a little fuzzy. Do you go with a simple model that everyone can understand, or a high-powered “black box” that promises more accuracy? This really boils down to a classic trade-off: interpretability vs. power.
Honestly, sometimes a straightforward model your sales team can actually get behind is worth more than a slightly more accurate one that nobody trusts. This is exactly where experienced AI consulting businesses make their mark—they help you find that sweet spot, ensuring the model actually gets used.
Matching Models to Business Problems
The algorithm you pick is a direct reflection of the question you’re asking. Let’s break down a few common scenarios I see all the time.
Forecasting a Number: Need to predict a specific amount, like next quarter’s revenue or a customer’s lifetime value? You’re in regression model territory. Think of these as the expert number-crunchers in your toolkit.
Predicting a Category: Is the question a “yes/no” or does it involve sorting things into buckets? You’ll want classification algorithms. They’re perfect for figuring out which customers might churn or flagging a transaction as “fraud” or “not fraud.”
Grouping Similar Items: If you’re trying to find natural patterns in your data without any pre-labeled examples, clustering algorithms are your best friend. A classic use case is segmenting your customer base into different personas for smarter marketing.
So, if an e-commerce company wants to predict how much a customer will spend next month, they’d fire up a regression model. But if that same company wanted to spot customers at risk of leaving, they’d pivot to a classification model like Logistic Regression.
Simple Models Versus Complex Powerhouses
It’s tempting to immediately reach for the most complex algorithm you can find, but that’s often a rookie mistake. Simple models like Linear or Logistic Regression are incredibly easy to explain. You can point to exactly which factors are driving a prediction, which is a massive win for getting buy-in from stakeholders or satisfying regulators in industries like finance.
On the other hand, more complex models like Random Forests or Gradient Boosted Machines can be astonishingly accurate. They excel at finding subtle, non-linear relationships in data that simpler models just can’t see. And the difference can be huge; research shows that ensemble methods like Random Forests can boost accuracy by 20-30% over single models. In the BFSI sector, for instance, these advanced algorithms can catch 99% of fraudulent transactions in real-time. Powerhouses like XGBoost have dominated machine learning competitions for years by drastically cutting down prediction errors. You can dig into the full research on predictive analytics market trends to see just how big of an impact these choices make.
I’ve learned that a key part of this job is knowing when ‘good enough’ is truly better. An 85% accurate model that your team understands, trusts, and actually uses is infinitely more valuable than a 90% accurate model that sits on a server gathering digital dust.
How a Partner Helps You Choose
That tug-of-war between a simple, clear model and a complex, powerful one isn’t always an easy call to make. This is where leaning on the experience of an AI and data consulting firm can be a game-changer.
An experienced partner helps you do three things really well:
Clarify the Trade-Offs: They’ll translate the technical jargon into business impact, showing you exactly what you gain in accuracy versus what you might lose in explainability.
Align with Business Needs: They make sure the model isn’t just a cool science project but something that slots right into your team’s workflow and helps them make better decisions.
Future-Proof Your Solution: They’ll help you pick algorithms that not only crack today’s problem but are also built to scale and be maintained as your business grows.
In the end, their job is to guide you to the right model, not just any model. That strategic thinking is what turns a predictive analytics project from a short-lived technical curiosity into something that delivers real, lasting value.
Training and Validating for Business Impact
Okay, you’ve got clean data and you’ve picked a promising algorithm. Now for the fun part: bringing your model to life. This is the training phase, where the model essentially studies your historical data to learn all the hidden patterns and relationships.
But here’s a critical piece of advice I give every client: training a model is only half the battle. The real test is validation. A model with impressive technical scores is completely useless if it doesn’t actually move the needle on your business goals.
Think of it like training a new sales hire. You wouldn’t just hand them a script and turn them loose on your customers. You’d role-play, test their product knowledge, and see how they handle tough questions. Your model needs that same level of rigorous testing to make sure it can perform when it really counts.
Beyond Technical Jargon: What Do Metrics Really Mean?
It’s way too easy to get lost in a sea of data science terms like “accuracy,” “precision,” and “recall.” While an AI consulting partner can help translate, it’s vital that you understand what they mean for your business. For instance, a model with 90% accuracy sounds amazing on the surface, right? But what does that actually mean for your day-to-day operations?
Let’s say you’re predicting customer churn. That 90% accuracy could be hiding a fatal flaw. What if the model is just really good at identifying your happy, loyal customers but completely misses the ones who are about to walk out the door? You’d be celebrating a high score while your churn rate doesn’t budge. This is where context is king.
Using Cross-Validation to Build a Robust Model
One of the biggest traps in predictive modeling is something called overfitting. This happens when a model doesn’t learn the general patterns in your data but instead just memorizes the specific examples it was trained on. It’s like a student who crams for a test—they can ace that one test but are lost when faced with a slightly different question.
An overfitted model looks like a genius in training but fails spectacularly when it sees new, real-world data.
To avoid this, we use a powerful technique called cross-validation. Instead of just splitting your data once, you split it into multiple parts, or “folds.” The model gets trained on a few folds and then tested on the fold it has never seen. This process repeats until every single fold has had a turn as the test set. It’s a much more honest way to gauge how your model will perform in the wild.
The most important question you can ask isn’t “How accurate is the model?” but “How will this model’s predictions change our decisions, and what is the value of that change?”
Let’s get practical. The metrics you focus on should directly answer a business question. This table breaks down the big three and what they really tell you.
Comparing Common Model Evaluation Metrics
Metric
What It Measures
When It’s Most Important
Accuracy
The overall percentage of correct predictions.
Good for balanced datasets where the cost of a mistake is the same on both sides (e.g., predicting if a customer prefers blue or red).
Precision
Out of all the positive predictions made, how many were actually correct?
Crucial when the cost of a false positive is high. Think: flagging a legitimate credit card transaction as fraud. That’s a very unhappy customer.
Recall
Out of all the actual positive cases that exist, how many did the model find?
Essential when the cost of a false negative is high. Think: failing to detect a faulty engine part. The consequences could be catastrophic.
See the difference? By zeroing in on the a metric that mirrors your specific business problem, you can evaluate the model based on its potential to save money, boost revenue, or delight customers. It’s this business-first mindset that separates a cool science project from a truly game-changing business solution.
Putting Your Model to Work with MLOps
A perfectly trained and validated predictive model is exciting, but it delivers exactly zero business value sitting on a data scientist’s laptop. The real magic happens when you move it from the lab into your live business environment where it can start making predictions that influence actual decisions.
This is the deployment phase, and it’s where the rubber truly meets the road. Getting this step right is just as critical as the model training itself. You’re not just flipping a switch; you’re integrating a dynamic, learning asset into your company’s operational nervous system.
Choosing Your Deployment Strategy
The first big decision is figuring out where your model will live and breathe. There’s no one-size-fits-all answer here; the right choice depends entirely on your company’s existing tech stack, budget, security rules, and the expertise you have on hand.
Your main options typically fall into three buckets:
Cloud Services: Platforms like AWS SageMaker, Google AI Platform, or Azure Machine Learning offer managed environments that take a lot of the headache out of deployment. This is often the fastest route, as they handle much of the underlying infrastructure for you.
On-Premise Servers: If you’re dealing with highly sensitive data or have strict regulatory compliance needs (think healthcare or finance), deploying on your own internal servers might be non-negotiable. This gives you maximum control but also means you need more in-house folks to manage it.
Edge Deployment: For applications needing split-second responses with almost no latency—like a fraud detection model on a point-of-sale device—you might deploy the model directly onto the device itself.
Many businesses start with cloud services for their flexibility and ability to scale, but the key is to choose a path that aligns with your long-term goals. For a deeper dive, our guide on approaches to machine learning model deployment offers a detailed breakdown.
The Rise of MLOps for Sustainable Value
Once your model is live, the work is far from over. In fact, it’s just beginning. This is where a crucial set of practices known as MLOps (Machine Learning Operations) comes into play. Think of it as DevOps, but specifically designed for the unique challenges of machine learning.
MLOps is the discipline of automating and managing the entire machine learning lifecycle. It’s the bridge that connects model development with business operations, ensuring your model remains reliable, accurate, and valuable over the long haul.
Without a solid MLOps strategy, you’re just building a model. With MLOps, you’re building a sustainable, ROI-generating system. It brings the automation and governance needed to manage models at scale, turning a one-off project into a repeatable, reliable business process.
Core Pillars of a Strong MLOps Framework
A robust MLOps framework isn’t just a single tool; it’s a culture and a set of practices built around a few key ideas. Nailing these is essential for keeping your models humming in a production environment.
Automated Pipeline (CI/CD): This is all about creating an automated workflow. Whenever the model is retrained with new data or the code is updated, it’s automatically tested, validated, and pushed into production without someone having to do it manually. It’s about speed and safety.
Performance Monitoring: The world changes, and so does your data. MLOps means setting up dashboards and alerts to constantly watch your model’s performance—not just on technical metrics, but on business KPIs, too. This helps you catch “model drift” (the natural decay in performance) before it hurts your bottom line.
Governance and Versioning: Who approved this model? What data was it trained on? MLOps establishes a clear paper trail by versioning everything: the data, the code, and the model itself. This is a lifesaver for compliance audits and for debugging when things inevitably go wrong.
By embracing these core principles, you move from simply building predictive models to creating a well-oiled machine that consistently delivers business value. For teams looking to formalize their process, exploring established MLOps Best Practices for Production AI can provide an excellent roadmap. This is how you make sure the model you launch today is still an asset for your business tomorrow.
Monitoring Performance and Proving ROI
Getting your predictive model live is a huge win, but don’t pop the champagne just yet. This is where the real work begins. The world your model was trained on is a snapshot in time, and the real world is messy, dynamic, and constantly in motion.
Customer tastes change, your competitors launch new campaigns, and economic shifts happen. All these factors contribute to a slow, silent killer of model performance: model drift.
Without a watchful eye, a model that was a star performer on day one can become a source of bad decisions by day ninety. That’s why a solid monitoring system isn’t just a “nice-to-have” feature; it’s the core insurance policy for your entire project. It’s how you make sure your model keeps delivering value long after the launch-day buzz fades.
Keeping an Eye on Model Drift
Model drift is what happens when the patterns the model learned from historical data no longer reflect reality. It’s subtle but totally inevitable. The trick is to spot it before it starts quietly costing you money.
To do this right, you need to monitor two things at once: the model’s technical health and its real-world business impact.
Technical Metrics: Keep a close watch on the same metrics you used during validation, like precision, recall, or MAE. A sudden drop or even a slow, steady decline in these numbers is your first clue that something’s off.
Data Drift: You also have to watch the input data. Is the new data coming in fundamentally different from what the model was trained on? For instance, if a new marketing campaign brings in a flood of younger customers, a model trained on an older demographic is going to start making mistakes.
Setting up automated alerts is a game-changer here. A simple dashboard that flags a 10% drop in precision or a major shift in a key feature’s distribution can be the early warning system that prevents a major headache down the line.
Tying Model Performance to Business KPIs
Technical stats are great for the data science team, but the C-suite doesn’t care about your F1-score. They care about results. The real measure of your model’s success is its impact on the key performance indicators (KPIs) you identified way back at the start.
Let’s go back to that customer churn model. You shouldn’t just be tracking its accuracy. You should be obsessing over the actual customer churn rate.
Your goal isn’t just to have an accurate model; it’s to reduce churn. If the model is 95% accurate but the churn rate is still climbing, the project is a failure. Period. Linking the model’s performance directly to business KPIs is the only way to prove its actual worth.
This focus on business outcomes is what separates a science experiment from a true business asset. It moves the conversation from technical jargon to tangible results that leadership can get behind.
A Simple Framework for Calculating ROI
Proving the Return on Investment (ROI) is how you justify the project’s cost and get the green light for future initiatives. You don’t need a convoluted financial model to do it. A straightforward framework can tell a powerful story.
The formula is as simple as it gets: (Value Gained – Project Cost) / Project Cost.
Here’s a practical way to break down the numbers:
Quantify the Value Gained: This is where you connect the model’s impact to real dollars.
Cost Savings Example (Predictive Maintenance): Your model correctly predicts 10 machine failures a month. Each failure normally costs $20,000 in downtime. The value gained is $200,000 per month.
Revenue Lift Example (Lead Scoring): Your model helps the sales team prioritize the right leads, and they start closing 5% more deals. If the average deal is worth $10,000, you can calculate the direct revenue lift from there.
Calculate the Project Cost: Tally it all up. This means software licenses, cloud computing bills, and, most importantly, the salaries of the team members who built and now maintain the model.
With these figures in hand, you have a clear, undeniable business case. If this feels daunting, an AI consulting partner can be invaluable. They’ve built these business cases countless times and can help you create ROI projections that are both realistic and compelling.
When you can show a strong, positive ROI, you change the entire narrative. Your data science team stops being a cost center and becomes what it should be: a proven engine for business growth.
Common Questions About Predictive Models
As you start exploring what predictive models can do for your business, it’s natural to have a few questions. I’ve seen both business leaders and their technical teams run into the same initial hurdles, so let’s tackle some of the most common ones head-on.
How Much Data Do I Need for a Good Model?
I get this one all the time, and the honest answer is: it depends. There’s no magic number.
For a straightforward problem, like a basic sales forecast, you might get a decent start with just a few thousand solid data points. But if you’re trying to do something more complex, like predict subtle shifts in customer behavior before they happen, you’re going to need a whole lot more.
The thing is, it’s not just about quantity. The real game-changer is quality and relevance. A smaller, cleaner dataset that perfectly captures the business dynamic you’re studying is infinitely more valuable than a massive, messy data lake full of noise.
My advice? Don’t start by chasing a huge dataset. Instead, pinpoint your most critical data sources first. Figure out if they’re clean and if they actually relate to the question you’re trying to answer. You’ll save yourself a world of headaches.
What Are the Most Common Mistakes to Avoid?
Most predictive modeling projects that go off the rails stumble over the same few, totally preventable issues. If you can sidestep these, you’re already way ahead of the curve.
The absolute biggest mistake is falling in love with the tech before defining the problem. You have to start with a clear business goal. What needle are you trying to move? Which KPIs matter? Tying your model to real-world value from day one is non-negotiable.
Another classic pitfall is glossing over data quality checks. You’ve heard it before, but “garbage in, garbage out” is the golden rule of machine learning for a reason. You can have the fanciest algorithm on the planet, but if you feed it junk data, you’ll get junk predictions. It’s that simple.
Finally, people often build a model and just… forget about it. They treat it like a one-and-done project. But the world changes, and your model’s performance will inevitably drift and degrade over time. You need a plan for ongoing monitoring and management (hello, MLOps!) to keep it relevant and accurate.
Can I Build a Model Without a Data Science Team?
It’s definitely getting easier, especially for simpler use cases. The new wave of AutoML platforms can handle a lot of the heavy lifting, which certainly lowers the barrier to entry for some basic predictive tasks.
But let’s be realistic. For custom, high-impact models that need to be woven into the fabric of your business, you need real expertise. The difference between a quick-and-dirty model and a strategic asset lies in the details—the clever feature engineering, the rigorous validation against business metrics, and a deployment that actually works with your existing tech stack.
This is often where bringing in an AI consulting partner makes a ton of sense. They’re not just bringing technical chops; they bring the strategic oversight to make sure the project is built right and actually delivers ROI. It’s a way to de-risk your first major AI initiatives and get some big wins on the board without the time and expense of building an entire team from scratch.
Ready to build predictive models that solve real business challenges? The team at NILG.AI specializes in creating custom AI solutions that drive growth and efficiency. Request a proposal
Like this story?
Subscribe to Our Newsletter
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
How to Improve Team Productivity: A Simplified Guide
Apr 8, 2026 in
Guide: How-to
Discover how to improve team productivity with AI-driven processes, engaged teams, and practical steps you can start today.
Transform Your Growth with custom ai software development in 2026
Apr 1, 2026 in
Guide: Explainer
Explore how custom ai software development can boost efficiency, cut costs, and deliver measurable value - find trusted partners and practical steps for 2026.
Discover how AI for customer service can transform your support operations. Learn practical strategies to reduce costs, improve satisfaction, and drive growth.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.