AI Automations • AI Strategy • AI4business • AI4tech •
Machine Learning Algorithms Explained: Practical Guide to AI Models
NILG.AI on Dec 30, 2025
?>
Think of machine learning algorithms as a set of instructions that let a computer learn from experience instead of being programmed for every single task. This guide is all about breaking down the main types—like supervised and unsupervised learning—and showing how they actually make a difference in business, whether that’s growing revenue or streamlining operations.
Your Practical Guide To Machine Learning Algorithms
Welcome. If you’re looking for a dry, academic textbook on machine learning, this isn’t it. This guide is built for business leaders who need to understand what these powerful algorithms are, how they function, and most importantly, how to use them to get tangible results. Let’s treat this as your playbook for connecting complex data science to a smart business strategy.
At its heart, a machine learning algorithm is just an engine designed to find meaningful patterns in your data. Instead of a developer hand-coding rules for every possible outcome, you feed the algorithm a ton of examples and let it figure out the logic on its own. It’s a lot like training a new employee by showing them past successes, not by giving them a thousand-page manual.
The Building Blocks of Business AI
The ideas behind machine learning aren’t exactly new. The term ‘artificial intelligence’ was first tossed around at the Dartmouth Conference way back in 1956, laying the groundwork for the tools that are reshaping entire industries today.
Now, these algorithms are the foundation of modern business intelligence. The proof is in the numbers: the global machine learning market is on track to explode from $93.95 billion in 2025 to a staggering $1,407.65 billion by 2034.
To get started, let’s sort these algorithms into three main buckets:
Supervised Learning: This is like learning with a teacher. The algorithm gets data that’s already labeled with the “right answers.” The goal is to learn the connections between the inputs and outputs so it can make accurate predictions on new, unseen data.
Unsupervised Learning: Here, the algorithm is on its own—no teacher, no answer key. It dives into unlabeled data to find hidden structures and groupings all by itself. This is fantastic for uncovering insights you didn’t even know you should be looking for.
Neural Networks: These are a more advanced class of algorithms, loosely inspired by the structure of the human brain. They’re built to handle seriously complex tasks, like recognizing images or understanding human language, and they’re the power behind many of today’s most sophisticated AI tools.
Our goal here is simple: to make these concepts clear so you can spot real opportunities in your own business. When you understand the what and the why, you can work more effectively with AI and data consultants to build a genuine competitive advantage.
We’ll dig into each of these categories throughout this guide, explaining how specific algorithms work and where they can fit into your strategy. If you want to go even deeper, check out these comprehensive resources on Machine Learning.
To make things even clearer, here’s a quick cheat sheet summarizing the three major types of machine learning we just covered.
Quick Overview of Major Machine Learning Algorithm Types
Algorithm Type
Core Function
Example Business Application
Supervised Learning
Learns from labeled data to make predictions or classify new data.
Predicting customer churn based on past behavior.
Unsupervised Learning
Finds hidden patterns and structures in unlabeled data.
Grouping customers into distinct segments for marketing campaigns.
Neural Networks
A subset of ML that uses interconnected nodes to solve complex problems.
Recognizing objects in images for automated quality control.
This table gives you a high-level view, but as you’ll see, the real power comes from knowing which tool to use for which job. Let’s get into the specifics.
Using Supervised Learning to Predict Business Outcomes
Supervised learning is the most direct way to leverage historical data for future insights. The core strategy is to use past outcomes to train a model that can predict future ones. We feed a supervised learning algorithm historical data that’s already been “labeled” with the correct answers—for example, which customers churned and which ones stayed. The algorithm then learns the patterns that connect specific behaviors to those outcomes.
The business objective is to make the model so proficient at spotting these patterns that it can accurately forecast what will happen with new, unseen data. This forms the basis of predictive analytics, empowering businesses to answer the critical question: “What’s next?”
This entire family of algorithms is your best bet when you have a specific target you’re trying to hit and a good chunk of past data to learn from. Let’s dig into the essential tools in this kit.
Linear and Logistic Regression: The Workhorses
When your goal is to predict a continuous numerical value, Linear Regression is the most straightforward and effective starting point. Want to forecast next quarter’s sales based on marketing spend? Linear regression finds that direct relationship, drawing a “best-fit” line through your data. Its speed and simplicity make it an ideal tool for establishing baseline predictions.
Logistic Regression, despite the name, is for classification. Its function is to predict a binary, yes-or-no outcome by calculating the probability that a new piece of data belongs to a specific category.
This makes it a powerhouse for strategic business questions:
Customer Churn: Will this customer cancel their subscription in the next 90 days?
Lead Conversion: Is this new lead likely to convert into a paying customer?
Credit Risk: Does this applicant meet the criteria for a low-risk loan?
It’s a foundational tool for proactive business decisions. You can see a real-world application in our guide on predicting customer churn, where it helps businesses retain revenue by identifying at-risk customers before they leave.
Decision Trees and Random Forests: Making Complex Choices
While regression models are excellent for linear relationships, business decisions often follow a series of “if-then” conditions. That’s the strategic advantage of Decision Trees.
A decision tree segments your data into smaller branches based on its most important features, creating an intuitive flowchart. For instance, a tree might determine that if a customer has been active for less than six months and has a low engagement score, their churn probability is 85%.
The strategic value of decision trees is their transparency. You can follow the exact logic from input to outcome, making it easy to explain the “why” behind a prediction to stakeholders and gain their trust.
However, a single tree can be overly sensitive to the specific data it was trained on. To create a more robust and accurate model, we use Random Forests.
A Random Forest is an ensemble method—it builds hundreds or even thousands of individual decision trees, each trained on a slightly different subset of your data. To make a final prediction, it aggregates the “votes” from all the trees.
This approach significantly improves predictive accuracy and stability, making Random Forests a preferred algorithm for high-stakes applications like optimizing marketing campaigns or detecting fraudulent transactions.
Finding Hidden Gems with Unsupervised Learning
Supervised learning requires you to know the answers in your historical data. But what if your goal is to discover patterns you don’t even know exist?
That’s the strategic value of unsupervised learning. It operates without any pre-labeled data, analyzing your information to find inherent structures, groups, and anomalies. This is how you uncover game-changing insights your competitors might miss.
Imagine being handed a massive, unsorted database of customer interactions. Unsupervised learning is the process that automatically groups those customers into meaningful segments based on their behavior, without you ever defining what those segments should be. For a business, this is how you turn raw data into strategic intelligence.
This approach is invaluable when labeling data is too costly, time-consuming, or impossible. Instead of asking “Is this customer in segment A or B?”, unsupervised learning asks, “What natural customer segments exist in our data that we can act on?”
Grouping Your Data with Clustering Algorithms
The most common application of unsupervised learning is clustering, which automatically groups similar data points. The go-to algorithm for this is K-Means.
Let’s say you have extensive customer transaction data but no clear segmentation strategy. K-Means can analyze purchasing frequency, average order value, and product preferences to create distinct customer personas automatically.
Suddenly, you can identify a “high-value loyalist” group, a “bargain-hunter” segment, and an “occasional big-spender” cluster. These aren’t segments you defined; they are data-driven insights the algorithm discovered. This is a massive strategic advantage for marketing, enabling you to move from generic messaging to targeted campaigns that increase engagement and ROI.
Unsupervised learning algorithms, like clustering and dimensionality reduction, uncover hidden patterns in unlabeled data, fueling anomaly detection and customer segmentation without human bias. Emerging prominently in the big data era post-2010, they’ve become indispensable for scalable insights. For business execs, this translates to gold: K-Means clustering segments customers with up to 85% accuracy, boosting retail revenue by 15-20% via targeted campaigns. In operations, these algorithms predict equipment failures, reducing downtime by 50% and saving manufacturers $50 billion yearly globally. Discover more about these impactful machine learning statistics and what they mean for business.
Simplifying Complexity with Dimensionality Reduction
Sometimes the challenge isn’t a lack of labels, but an overwhelming amount of information. Datasets with thousands of features can be slow, costly to process, and full of irrelevant noise. This is the exact problem dimensionality reduction is designed to solve.
The strategy is analogous to condensing a 100-page report into a one-page executive summary. You lose minor details but retain the critical insights, making the information easier to analyze and act upon.
A leading technique for this is Principal Component Analysis (PCA). PCA excels at identifying the core patterns in your data and consolidating related features into a smaller number of more impactful ones. This has direct business benefits:
Better Model Performance: By filtering out noise, PCA helps other ML models run faster and deliver more accurate results.
Clearer Data Visualization: It allows you to represent complex, high-dimensional data in 2D or 3D, making it possible to visually identify trends and clusters.
Lower Operational Costs: By focusing on essential features, you can reduce data storage and processing expenses.
When explaining machine learning algorithms, unsupervised learning is the key to turning raw, unlabeled data from a cost center into a strategic asset. Partnering with an AI and data consulting firm can help you apply these methods to discover valuable customer segments, detect anomalies, and streamline your data operations without the burden of manual labeling.
Neural Networks: The Brains Behind Modern AI
While the algorithms we’ve discussed are powerful, the most transformative AI applications today are driven by neural networks. Inspired by the structure of the human brain, these algorithms process information through layers of interconnected digital ‘neurons’.
A neural network is not a single algorithm but a system of tiny specialists working together. Each neuron handles a small piece of the puzzle, and by passing information from one layer to the next, the network as a whole can identify incredibly subtle and complex patterns that other methods would miss. This is the technology behind real-time language translation and advanced computer vision systems.
The Foundation of Advanced AI
Neural networks are the engines that come closest to mimicking human cognition, revolutionizing fields like computer vision and natural language processing. The machine learning segment, driven by these nets, is a huge slice of the overall AI pie. For businesses, this translates into some seriously powerful tools. Take computer vision, a market on track to blow past $58 billion by 2030. This tech is already letting manufacturers achieve 99% accuracy in defect detection, cutting down operational waste by 20-30%. You can dig into the numbers in the full AI market research from Precedence Research.
This layered structure allows neural networks to solve highly complex problems. However, they aren’t one-size-fits-all; different architectures are engineered for specific business challenges.
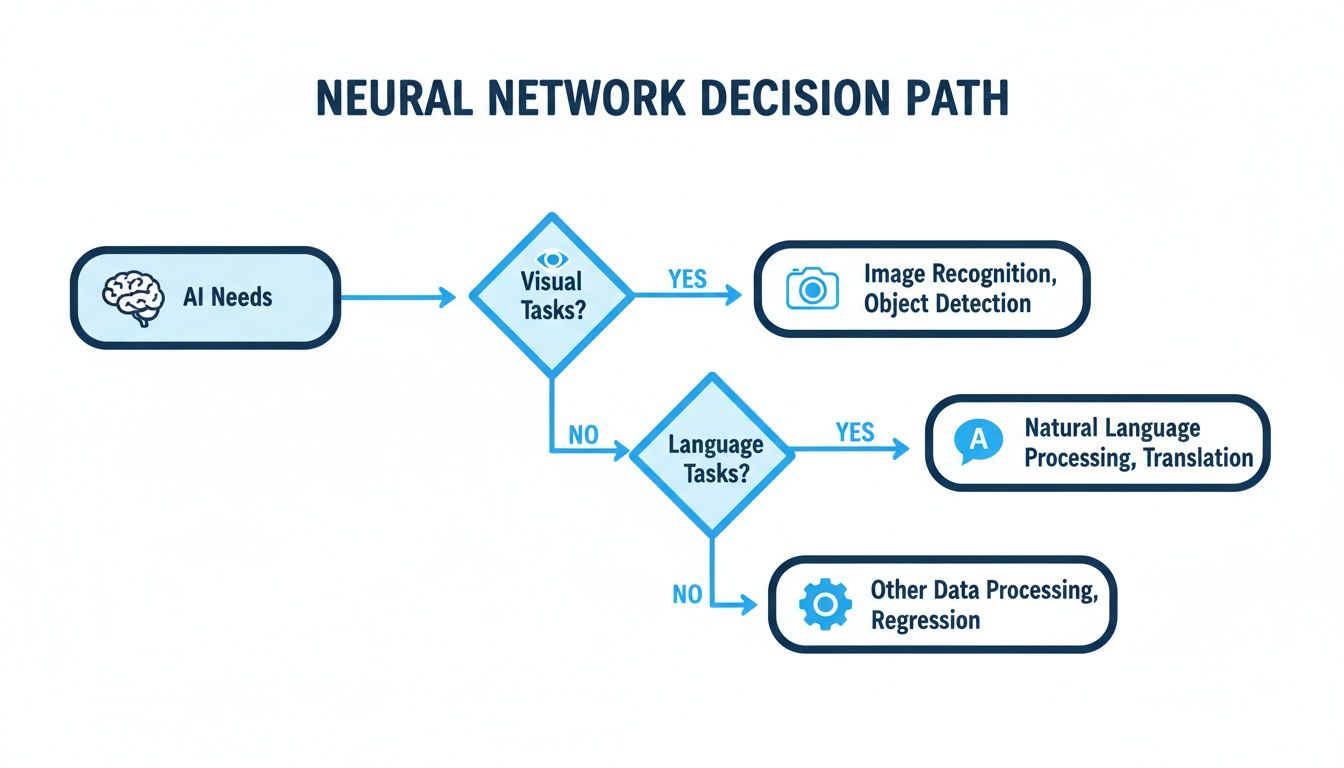
CNNs: Giving Your AI a Sense of Sight
When your business problem revolves around visual data, you need a specialized tool: Convolutional Neural Networks (CNNs). They are designed to “see” and interpret images by recognizing features in a hierarchy—starting with simple lines and edges before building up to complex shapes and objects.
Imagine a CNN monitoring products on a factory assembly line:
Layer 1: It identifies basic features like lines and curves.
Layer 2: It combines those lines to recognize simple shapes, like a circle or screw head.
Layer 3: It identifies combinations of shapes as a complete product component.
Final Layer: It makes a business decision: “pass” or “fail.”
This makes CNNs indispensable for automating any visual inspection task. A manufacturer can use a CNN to detect microscopic defects in parts, a job that is tedious and error-prone for human inspectors. A retailer can use one to automatically categorize thousands of product images for their online store.
By translating raw visual data into actionable business intelligence, CNNs help organizations improve quality control, streamline inventory management, and create innovative customer experiences. They are a prime example of practical AI delivering measurable operational results.
RNNs: The Memory and Ears of AI
CNNs excel with static, spatial data like images. But for problems that evolve over time, such as forecasting sales or understanding conversational context, you need a different architecture: a Recurrent Neural Network (RNN).
RNNs possess a unique form of memory. They retain information from previous steps in a sequence, allowing them to understand the context of what’s happening now. This is what makes them so effective. When an RNN processes a sentence, it doesn’t just see isolated words; it understands the meaning built up by the preceding words. This capability is critical for applications like customer service chatbots, which must follow the flow of a conversation to be effective.
Their ability to process sequential data makes them a cornerstone of most language-based AI systems. To understand how these models are customized for specific business tasks, see our guide on fine-tuning vs. prompt engineering.
From customer service chatbots that improve user satisfaction to systems that forecast financial market trends, RNNs help businesses make sense of dynamic data. Working with an AI partner can help you identify opportunities to use these powerful algorithms to automate complex workflows and build innovative, AI-powered products.
How to Choose the Right Algorithm for Your Business
Knowing the available machine learning algorithms is one thing; knowing which one to deploy for a specific business challenge is another. This is where strategy meets execution, transforming a business problem into a clear, actionable AI solution.
The decision is primarily a business one, guided by your goals, your data, and your operational needs. The process begins with asking practical, outcome-oriented questions, not technical ones.
Start With Your Business Problem
Before considering any algorithm, define your objective in clear business terms. A vague goal like “we want to use AI” leads nowhere. Get specific.
Are you trying to:
Predict a future value? To forecast sales or estimate customer lifetime value, you’re dealing with regression. Linear Regression or Random Forests are strong starting points.
Classify something into categories? For tasks like flagging fraudulent transactions or sorting support tickets, you need a classification algorithm like Logistic Regression or a Decision Tree.
Discover hidden groups or patterns? To find natural customer segments in your user base without predefined labels, unsupervised algorithms like K-Means Clustering are your best tool.
The clearer your business question, the shorter your list of potential algorithms becomes. The goal isn’t to find the most complex algorithm; it’s to find the simplest one that solves your problem effectively.
Consider Your Data and Resources
Your data is the fuel for any algorithm, and its characteristics will heavily influence your choice. Is your dataset large or small? Is it clean and well-labeled, or is it raw and inconsistent?
For instance, neural networks can deliver state-of-the-art accuracy, but they require massive amounts of data and significant computational resources. If you’re working with a limited dataset, a simpler model like Logistic Regression might not only be more practical but could also perform better by avoiding overfitting.
This is a critical strategic point. The best AI and data consulting partners prioritize solutions that fit your real-world constraints, not just what’s theoretically possible.
The flowchart below shows how the type of problem dictates the right tool, even within a single, complex family of algorithms.
As you can see, the specific business need—whether it involves analyzing images or understanding text—determines which specialized neural network architecture you’ll need.
Balance Accuracy With Interpretability
Finally, you must weigh two competing priorities: how accurate does the model need to be, and how important is it to understand why it made a certain decision? This is a crucial trade-off.
A complex model like a Random Forest might achieve 95% accuracy but operate as a “black box,” making its reasoning difficult to explain. In contrast, a Decision Tree might be 88% accurate but provides a completely transparent, step-by-step flowchart of its logic.
In regulated industries like finance or healthcare, where every decision must be auditable, that transparency is a non-negotiable requirement.
Choosing Your Algorithm A Problem-Solving Guide
To help you connect these concepts to real-world challenges, this guide maps common business problems to their best-fit algorithms, keeping practical considerations in mind.
Business Problem
Best-Fit Algorithm(s)
Key Considerations (Data, Interpretability)
Forecasting Quarterly Sales
Linear Regression, Random Forest
Requires historical sales and feature data. Linear Regression is highly interpretable; Random Forest offers higher accuracy but is less transparent.
Identifying High-Value Customers
K-Means Clustering
Works with unlabeled customer data (purchase history, engagement). The output is distinct groups that require business interpretation.
Predicting Customer Churn
Logistic Regression, Decision Tree
Needs labeled historical data of churned vs. active customers. Both are highly interpretable, making it easy to see churn drivers.
Detecting Fraudulent Transactions
Random Forest, SVM
Requires labeled fraud data. Accuracy is paramount, so the “black box” nature of these models is often an acceptable trade-off.
Ultimately, choosing the right algorithm is less about technical expertise and more about a deep understanding of your business problem and the strategic trade-offs involved. This pragmatic approach ensures you build a solution that delivers real business value.
Your Path to Successful AI Integration
Understanding machine learning algorithms is the first step. The real value comes from applying them to cut costs, create revenue, or improve operational efficiency. The journey from concept to a real-world deployed solution requires connecting clear business goals with deep technical expertise.
This process doesn’t start with code; it starts with a strategic conversation to identify where AI can solve a genuine business problem. This initial step ensures every AI project is tied directly to a measurable outcome, avoiding “tech for tech’s sake” initiatives.
From Strategy to Execution
Once a clear target is defined, the hands-on work follows a proven data science roadmap:
Data Preparation: Raw business data is rarely ready for modeling. This stage involves cleaning, organizing, and structuring your data so an algorithm can learn from it effectively.
Model Development: Here, we select the right algorithm and train it on your data. A retail company, for instance, might train a Random Forest model to identify customers with the highest propensity to respond to a new marketing campaign.
Seamless Integration: A model is useless if it isn’t accessible. The final, critical phase is integrating the AI solution into your existing software and workflows so your team can use it to make better decisions.
Consider a logistics company struggling with delivery delays and high fuel costs. By applying regression algorithms to historical route and traffic data, they could build a model to predict optimal driver routes in real-time. The result: a 15% reduction in fuel costs and a significant improvement in on-time delivery rates. That is the tangible impact of turning an algorithm into a business solution.
The most successful AI solutions are born from a deep understanding of both the business problem and the technological capabilities. With the right knowledge and a solid partner, any business can leverage machine learning for a true competitive advantage.
The work isn’t finished once the model is built. True success comes from proper deployment and ongoing management to ensure it continues to deliver value. To learn more about this critical final step, see our guide on best practices for machine learning model deployment and how to ensure your AI investment pays off.
A Few Common Questions We Hear
If you’re a business leader navigating machine learning, you’re not alone. We get asked a lot of questions. Here are a few of the most common ones, answered from a practical, business-focused perspective.
“How Much Data Do We Actually Need?”
This is the classic “it depends” question, but here is some real-world guidance. A simple model, like a Linear Regression for sales forecasting, can often provide value with just a few thousand clean data points. In contrast, a deep learning model for medical image analysis might require hundreds of thousands of examples to learn effectively.
The most critical factor isn’t volume, but quality and relevance. A smaller, well-curated dataset that directly addresses your business problem will always outperform a massive, messy data swamp. A good AI consulting partner can assess your current data assets and determine if they are sufficient to start, or outline a strategy for what you need to collect.
“What’s a Realistic Timeline for Building and Deploying a Model?”
Building a production-ready model is not a one-week task. For a well-defined pilot project—such as a customer churn predictor using a clean dataset—a realistic timeline from initial concept to a working prototype is typically 4 to 8 weeks.
More complex projects, especially those requiring significant data engineering or integration with legacy systems, can take several months.
The most effective approach is to start small and demonstrate value quickly. Successful AI initiatives often begin as a focused proof-of-concept. This validates the ROI and builds internal momentum before you commit to a full-scale production system, minimizing risk and securing early wins.
“So, What’s the Single Best Algorithm?”
There is no single “best” algorithm. The best algorithm is simply the right tool for your specific job.
Think of it this way: a Decision Tree is an excellent choice when you must be able to explain why a prediction was made to your team or a regulator. For that same problem, a Random Forest might provide higher accuracy, but you would sacrifice that clear explainability.
This is why the process should always start with your business goals, not with a pre-selected algorithm.
Ready to turn these questions into a concrete plan? NILG.AI excels at building practical roadmaps that connect the right machine learning tools to real-world business outcomes. Request a proposal
Like this story?
Subscribe to Our Newsletter
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
Transform Your Growth with custom ai software development in 2026
Apr 1, 2026 in
Guide: Explainer
Explore how custom ai software development can boost efficiency, cut costs, and deliver measurable value - find trusted partners and practical steps for 2026.
Discover how AI for customer service can transform your support operations. Learn practical strategies to reduce costs, improve satisfaction, and drive growth.
How Might We Statements: Turn Challenges into Opportunities
Mar 15, 2026 in
Guide: Explainer
Discover how might we statements transform complex challenges into real opportunities. Learn practical crafting tips, workshops, and real-world examples.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.