Let’s discuss a common scenario in AI consulting. The client provides access to data sources in formats such as CSVs or databases that aren’t in a production environment. Why? Usually, they’re exploring the value of the project, do not want to disclose too much data and want to prevent technical problems from happening at the initial stages. We understand that!
Then, we validate the idea and develop a solution that successfully solves the challenge on internal pilots. Now, the client is excited and wants to push it into production… oh, no! You need to change the entire code to adjust to the new environment.
How can we prevent that from happening? Here is where the Repository Pattern can become real handy, helping us to save time and effort.
Repository Pattern – What is it?
The Repository Pattern is a well thought and documented way of dealing with data sources.
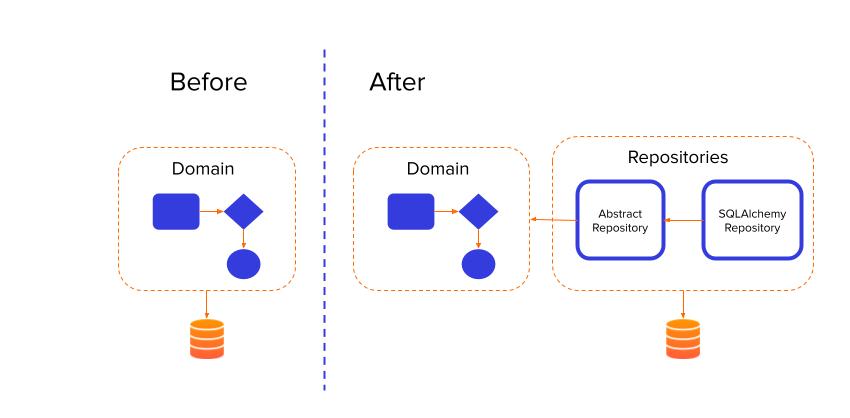
It consists of abstraction over persistent storage, hiding the boring details of data access by pretending that all of our data is in memory.
As the name tells us, the main character of this design pattern is the repository. The repositories are a set of objects and classes that help us encapsulate the logic needed to access the data sources.
The repositories sit between the domain model and the data sources, allowing us to decouple our model layer from the data layer.
Which problems will the Repository Pattern help to solve?
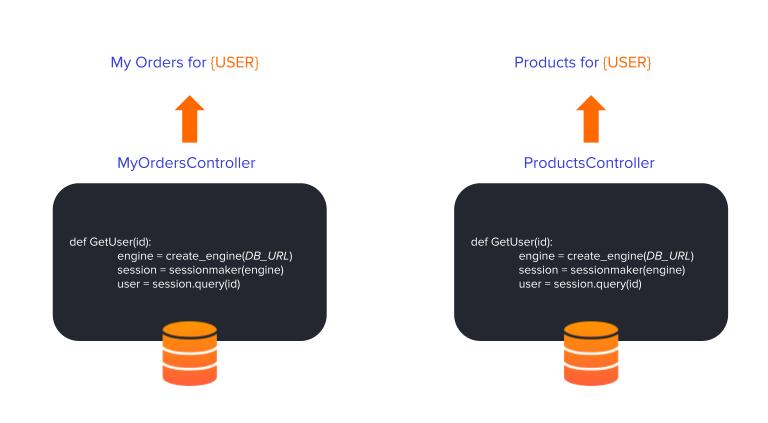
Let’s consider a scenario where we have a website for an online store, where we have several pages. One page can be the Product’s page, and another one can be the My Orders page. In both pages, there is a header welcoming the user with a text box saying “Welcome John Doe!”.
Taking into account the current solution, let’s analyze the problems with that design:
The first problem is the fact that both MyOrdersController and ProductsController implement their private method in order to get the user. In programming, this is called code duplication which violates the DRY (Don’t Repeat Yourself) principle. By doing this, we’re adding complexity to our code, which makes it harder to make changes, which leads to spending more time and effort maintaining the code.
For instance, let’s imagine we need to change the way we access the User (e.g., DB change). The current solution requires changes in both methods, meaning we spend more time analyzing the impact of a DB change, since there are more than one place where we need to look at in the code.
The second problem with this design is that we’re asking the controllers to manage and understand how to access the data.
In this case, since the data is stored in a Database, that means the controllers are responsible for managing stuff like DB connections and connection strings.
This means that we have a strongly coupled architecture, since we are linking our controllers to the infrastructure used to store our data, which translates to less flexible and hard to maintain code.
The third problem is the fact that the code is hard to test. Let’s imagine that our data source is an SQL Server database. If we wanted to test our code, we would need to set up the SQL Server, get the connection string, set up the Entity Framework, generate the Test Database, insert the data and only then could we test the code, assert the errors and act upon those errors. This chain of actions are not practical at all, and make it difficult to write clean and testable code.
How to implement the Repository Pattern?
Let’s walk through how we can use the Repository Pattern in order to improve our design.
As described in the beginning of this blog post, the Repository Pattern is all about abstracting the data sources from the application layer. Which benefits does this design bring us?
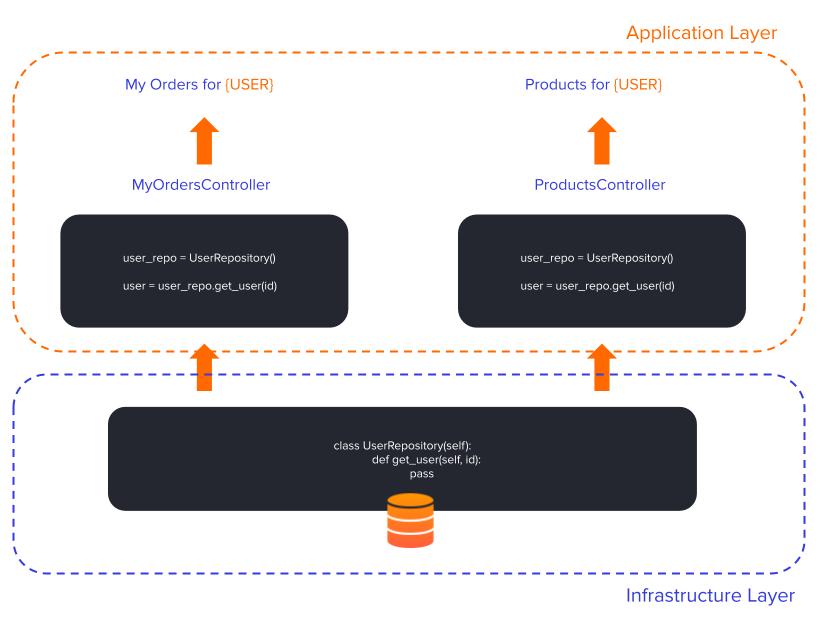
First of all, you can see that all the logic related to accessing the data is now centralized in one User Repository and we no longer have code duplication issues. In this way, our code is respecting the solid principle of DRY. Both our controllers are calling the same method from a single repository, in order to get the user information. With this approach, our code is better maintained since we are simplifying our architecture, making it more flexible and easier to change.
Another benefit is that the application layer is now decoupled from the infrastructure layer. That gives us the possibility to change both layers independently.
What we also did, was to change the responsibility to interact with the data source from the controllers to the repository. That allows us to use interfaces to define the behavior our controllers can expect from the repository and, that way, we encapsulate the data source implementation details. With these improvements, we gained flexibility and scalability when considering design choices on how to access the data. So if we need to change the way we access our data (API, NOSQL, CSV file, etc), we only need to change the repository, without worrying about breaking the application layer.
What are the 3 best practices implementing the Repository Pattern?
Let’s walk through some of the best practices when implementing the Repository Pattern.
Implement CRUD Operations
One good practice is to implement CRUD operations on the repository. Whenever we’re implementing the Repository Pattern, we should always try to design the repositories to work with CRUD operations. That facilitates the way we interact with the repository. So, for instance, in the previous design in the User Repository, we could have methods such as:
get_user(id)
list_users(**filters)
add_user(**kwargs)
update_user(**kwargs)
delete_user(id)
One Repository per Business Object
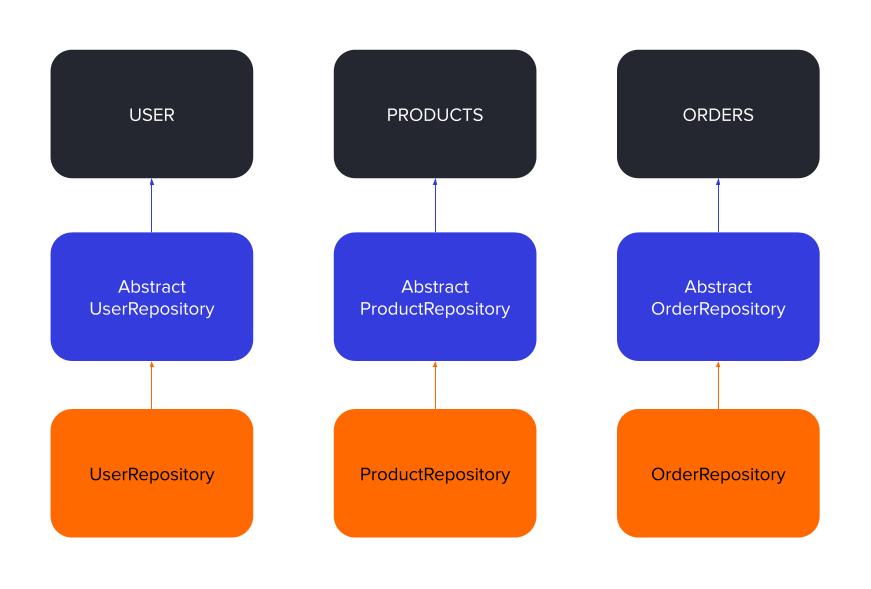
Another good practice is to have one repository per business object.
The Single Responsibility Principle says that “every class should have only one reason to change”, so taking that in consideration, it makes sense that we have one repository for each business object in our data. So, for instance, if we have data about users, products and orders, we should implement 3 repositories:
Provide a Contract or Interface
As you can notice in the figure above, for each repository there is an abstract repository, which is an abstract class. An abstract class is a class that can not be instantiated. However, we can create other classes that inherit the properties from the abstract class. You can think of the abstract class as a blueprint or a contract, where we define all the methods that a child class will inherit. What that means is that the abstract class will not have any logic implementation, but only the skeleton of the class. That logic will be implemented in a child class that inherits from the abstract class.
Why is this a good practice? Well, this helps us to maintain a loosely coupled architecture, contributing to the abstraction of the last layer where we have our data source connections. This way, we don’t need to directly inject concrete classes in our controllers, we just pass an interface (the abstract class), so the controllers know what to expect from the infrastructure layer.
This allows us to use different implementations of the same interface within our architecture. One really good example is, for testing purposes, we just need to replace the database with in-memory data like a return of a list or an array, for example, without having the need to change the way the controllers interact with the interface.
Conclusions
As detailed in this blog post, the Repository Pattern can be life changing for software developers or data scientists. Whether developing a solution to a client, when often we don’t have the production data source at the earlier stages, or developing a POC to a product using mock data, the Repository Pattern saves us time and effort in the long term and make our code cleaner and easier to maintain, by having a loosely coupled architecture, allowing us to change both application and infrastructure layers independently.
Like this story?
Subscribe to Our Newsletter
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
Unlock Ai First Meaning: Strategic Guide for 2026
Jun 22, 2026 in
Guide: Explainer
Unlock the true ai first meaning for your business. Get a 2026 strategic roadmap, practical examples, and avoid common pitfalls.
AI for Business Growth Your Practical Strategy Guide
Jun 17, 2026 in
Guide: Explainer
Discover how AI for business growth can boost efficiency, improve decision-making, and create deeper customer connections. Get actionable strategies now.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.