Multiple Instance Learning (MIL) is a form of weakly supervised learning where training instances are arranged in sets, called bags, and a label is provided for the entire bag, opposedly to the instances themselves. This allows to leverage weakly labeled data, which is present in many business problems as labeling data is often costly:
Medical Imaging: Computer-aided diagnosis can be trained with medical images for which only patient diagnosis for diseased regions are available, instead of local annotations.
Video/Audio: Video or audio tags are only often available for the whole video, and it’s relevant to know when that happens (e.g. this video contains a cat and a human)
Text: Document Classification, where you want to know, for instance, if a certain website (composed of several web pages) is about one specific topic. You will have multiple pages with irrelevant information where that topic is not present.
Marketing: Often, marketing campaigns are sent to a group of people and it’s not clear which person was impacted by it.
Time Series: In some industry cases, where you have gas/water meters, and know the total amount per month, you might want to estimate the amount at a more granular level (e.g. days).
Would you like to know more about Multiple Instance Learning?
The literature mostly focuses on applications of MIL for classification. However, there are some applications of MIL for regression, ranking, or cluster, which will not be focused here. For resources on it, please refer to this review paper.
Also, besides this blog post, we have an online course where we discuss in-depth Multiple Instance Learning, how to implement it, common errors and how to avoid them, and some practical examples from our consulting practice. You will also learn about other techniques such as Semi-Supervised Learning, Self-Supervised Learning, among others.
Course
The Machine Learning Spectrum
Master Multiple Instance Learning and several other techniques in our course.
In the standard MIL assumption, negative bags are said to contain only negative instances, while positive bags contain at least one positive instance. Positive instances are labeled in the literature as witnesses.
An intuitive example for MIL is a situation where several people have a specific key chain that contains keys. Some of these people are able to enter a certain room, and some aren’t. The task is then to predict whether a certain key or a certain key chain can get you into that room.
For solving this, we need to find the exact key that is common for all the “positive” keychains – the green key. We can then correctly classify an entire keychain – positive if it contains the required key, or negative if it doesn’t.
This standard assumption can be slightly modified to accommodate problems where positive bags cannot be identified by a single instance, but by its accumulation. For example, in the classification of desert, sea and beach images, images of beaches contain both sand and water segments. Several positive instances are required to distinguish a “beach” from “desert”/”sea”.
Characteristics of Multiple Instance Learning Problems
There are some common characteristics of MIL problems, as defined in the literature, which will be discussed next.
Task/Prediction: Instance level vs Bag Level
In some applications, like object localization in images (in content retrieval, for instance), the objective is not to classify bags, but to classify individual instances. The bag label is the presence of that entity in the image.
Note that the bag classification performance of a method often is not representative of its instance classification performance. For example, when considering negative bags, a single False Positive causes a bag to be misclassified. On the other hand, in positive bags, it does not change the label, which shouldn’t affect the loss at bag-level.
Bag Composition
Most existing MIL methods assume that positive and negative instances are sampled independently from a positive and a negative distribution. This is often not the case, due to the co-occurrence of several relations:
Intra Bag Similarities
The instances belonging to the same bag share similarities that instances from other bags do not. In Computer Vision applications, it is likely that all segments share some similarities related to the capture condition (e.g. illumination). Another option is overlapping patches in an extraction process, as represented below.
Instances co-occur in bags when they share a semantic relation. This type of correlation happens when the subject of a picture is more likely to be seen in some environment than in another, or when some objects are often found together.
In some problems, there is an underlying structure (spatial, temporal, relational, causal) between instances in bags or even between bags. For example, when a bag represents a video sequence – for instance, identifying the frames of a video where a cat appears knowing only there’s a cat in that video – all frames or patches are temporally and spatially ordered.
Label Ambiguity
Label Noise
Some MIL algorithms, especially those working under the standard MIL assumption, rely heavily on the correctness of bag labels. In practice, there are many situations where positive instances may be found in negative bags – due to labeling errors or inherent noise. For example, in computer vision applications, it is difficult to guarantee that negative images contain no positive patches: An image showing a house may contain flowers, but is unlikely to be annotated as a flower image.
Label noise occurs as well when you have different bags with different densities of positive events. For instance, we have an audio recording (R1) of 10 seconds containing only a total of 1 second of the tagged event in it and another audio recording (R2) of the same duration in which the tagged event is present for a total of 5 seconds. R1 is a weaker representation of the event compared to R2.
Different Label Spaces
It is possible to extract patches from negative images that fall into this positive region. In the example shown below, some patches extracted from the image of a white tiger fall into another concept region due to being visually similar to it.
Multiple Instance Learning Models
There are multiple models that can be used for MIL – either at instance or bag-level classification. A few examples are shown next:
Bag-Level Classification
Bag of Words approach
A bag can be represented by its instances, using methods such as an image embedding, and determining the frequency of each instance in a bag. A classifier is then trained on this histogram, to determine whether a bag is positive or not.
Earth Mover Distance Support Vector Machine (EMD-SVM)
The EMD-SVM is a measure of the dissimilarity between two distributions (e.g. via an image embedding as well). Each bag is a distribution of instances and the EMD is used to create a kernel used in an SVM.
Alternative applications of SVMs (mi-SVM and MI-SVM) were developed for multiple instance learning applications. Classically, SVMs try to determine the maximum margin between instances. For MIL, since the goal is to have at least one instance in a positive bag as positive, the margin is changed so that condition occurs: at least one instance in a positive bag should have a large positive margin.
After determining the decision function, the instances’ class can be recovered.
Mixed
Neural Network with pooling
With a bag-level label, we can have a latent space containing the probability of each segment (using a sequence-based input). By applying a pooling operator (max/average pooling), there’s just a single score associated with a bag. After training, if you want to do an instance-level prediction, the last pooling layer can be removed.
Usually, max pooling is used for classification problems, while average pooling is applied to regression problems.
Neural Networks with Attention Mechanisms
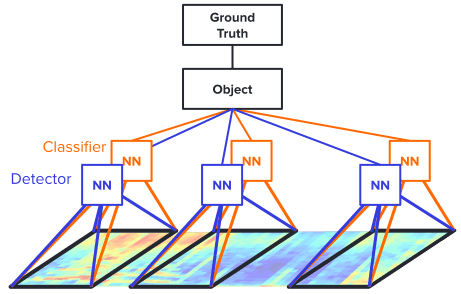
Attention Mechanisms can also be applied to these kinds of problems. Consider the image below, for audio-level event detection, which uses both a detector and a classifier (symmetric) with just the video-level label to create two separate models. The output of the classifier indicates how likely a certain block has tag k. The output of the detector indicates how informative the block is when classifying the k-th tag. This way, the model determines how informative a block is for classifying a certain tag.
This blog post has described the concept of Multiple Instance Learning, its major challenges, and some examples of algorithms that can be used. Although applying MIL is not ideal, and very often, it seems impossible to train models with sparse annotations, there are tools designed specifically to tackle this barrier and obtain satisfactory results.
These are just some of the tools which can be used for this purpose. Hopefully, it has given you some new ideas for applying this to your projects – enroll in our online course for information about Multiple Instance Learning and other learning paradigms.
Course
The Machine Learning Spectrum
Master Multiple Instance Learning and several other techniques in our course.
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
Unlocking Process Standardization Benefits for Your Business
Apr 29, 2026 in
Guide: Explainer
Discover the key process standardization benefits that slash costs, boost quality, and set your business up for sustainable growth. Start optimizing today.
What Is Enterprise AI and How Does It Drive Business Value
Apr 22, 2026 in
Guide: Explainer
Discover what is enterprise AI and how it transforms business operations. This 2026 guide explains its core components, use cases, and implementation roadmap.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.