“The more I see, the less I know” might be a saying, but it does not apply to AI models. It’s well known that the performance of an artificial neural network is highly dependent on the volume and on the diversity of the data that was shown to the model. This happens because exposing the models to diversity helps them select relevant features and mitigate potential bias, i.e. to understand the objects of study and to better perform their tasks.
Getting data to feed such models might seem trivial since data is all around us. However, getting access to well-structured, labeled, copyright-free, and non-private data is still a pain for most data scientists.
To overcome this, AI experts have come up with several approaches to optimize the learning process, in particular, smart architectures for Self Supervised Learning models.
In this blog post, we (re)introduce you to Self Supervised Learning, along with one of our favorite strategies – Siamese Models – and possible applications. If you want to learn even more about Self Supervised Learning and other Machine Learning techniques enroll to our online course:
What’s Self Supervised Learning?
Supervised Learning is a machine learning approach that receives input data along with a specific target and aims to learn the data patterns and the transformation function that converts the input into the output. On the other side of the coin, we have Unsupervised Learning which is a method that needs no target to fulfill its mission, since it aims primarily to find patterns in data distributions.
Then, we have Self Supervised Learning, which is an Unsupervised Learning method since it uses unlabeled data and has the particularity of creating synthetic labels to behave as a Supervised Learning model.
These labels can be created by applying trivial transformations to the data. Here are some examples:
Objective
Transformation
Synthetic Label
Quantify image rotation
Random rotation
Rotation angle
Assess data Quality
Insertion of random values into a data frame
Binary flag for corrupted data
Image Colorization
RGB to black and white
RGB image
The Self Supervised models can be used in two different manners:
To generate predictions, in case the synthetic task corresponds to the main purpose of the model. E.g. train an image colorization model and use it to colorize black and white pictures.
To share its knowledge (by sharing its weights) with a Supervised Learning model with a different task. E.g train a Self Supervised model to detect if a picture is flipped and use the weights to initialize a model for object detection.
Course
The Machine Learning Spectrum
If you want to learn more about self-supervised learning, and other learning methods, check this course.
In NILG.AI, one of our favorite model architectures is the Siamese Networks. Siamese models consist of a model architecture with two (or more) branches, where each of them receives a different input. The weights of the branches might be shared or not and, at the final layer of the model, the outputs of the branches are compared.
Below you can see an example of an architecture for a siamese network applied to images, which we implemented to demonstrate to you the usefulness of these models:
This model has two branches that share weights. Each branch is composed of an encoder (CNN model for feature extraction) and a block of fully connected layers. The output of the two branches is then merged to compute the loss function.
To feed the model, we implemented a data generator that takes an image as input, applies a transformation defined by the user, and returns the two transformed images along with a synthetic target. The transformation function is defined in the model initialization but the magnitude of the transformation should be a random value that fits the given range. For example, to teach a model how to learn the orientation of the objects, it can be passed a rotation function along with the range of possible angles. The data generator will select two random angles from the given range and it will rotate the input image considering those angles, creating two different transformed images. The generator compares the two angles: if the angle from the first transformation is higher than the angle from the second transformation, it sets the synthetic label as 1, otherwise, the label is set as 0. In the end, the generator yields the two transformed images and the corresponding synthetic label.
Baseline Results
As an exploratory exercise, NILG.AI developed several transformation functions and trained a model with a very small dataset (less than 100 samples) of images randomly picked from Unsplash. The trivial transformations included:
Blur addition
Image rotation
Brightness deviation
The siamese model architecture was adapted to each transformation function creating three different models. A single trained branch from the siamese model was then used to compute the predictions on single images and here are the results observed.
Note: The predictions correspond to the output of the last fully connected layer of the branch. These values should be interpreted as proxies of the magnitude of the transformations. To use these outputs as predictions of the real value of the transformation, e.g. rotation angle, the output should be calibrated.
Blur Addition
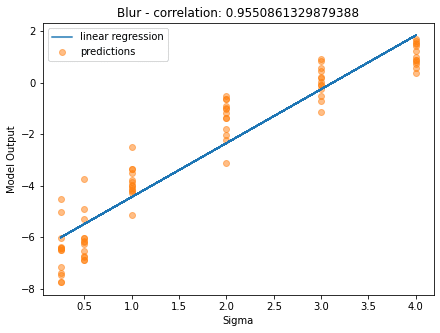
For the blur addition, we applied a gaussian blur filter with fixed window size and a variable sigma value. To test the model performance, we applied blur addition with different values of sigma to the same image and extracted the predictions from the model. In the image below, we can observe that the model output increases with the sigma, being able to distinguish the intensity of the transformation.
In the second test phase, we repeated the transformations in each image of the test set and extracted the correlation between the model output and the sigma. This model has a 95,5% correlation with the ground truth, having the potential to be used as a blur detector.
Finally, we extracted the predictions for the original images of the test set, presenting some examples in the grid below. Since we were dealing with high-quality images, the model returned low values for blur detection (usually lower than -6.4), except for the image with the coffee filter which contains a significant background blur.
Image Rotation
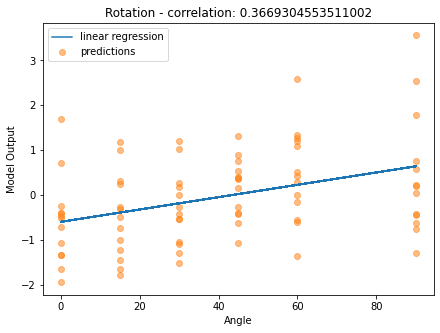
We repeated the same test for the rotation model, this time changing the angle value, getting the results below.
The correlation value for this model was 0.37, which is understandable considering the difficulty of the task. Recognizing if an object is tilted and identifying the correspondent angle implies prior knowledge of the object itself, which is hard to teach to a model with a set of only 100 images representing different objects. Therefore, to use this model as a rotation corrector, we might need to use a lot more data or put more constraints on the image selection, e.g. select images of interior decoration, only.
Since this task requires a higher knowledge of the objects, it can also be used as a secondary task of a multitask learning model. This strategy can help the model to better learn the features of the objects of interest avoiding extra labeling costs.
Brightness Deviation
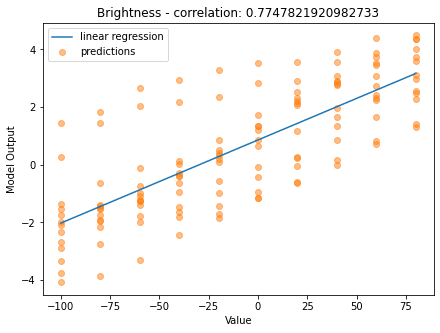
The same analysis was made for the brightness model. For this example, the transformation relies on manipulating the value (V) on the HSV color representation by adding a random number. When testing the model for the same transformed image, we can observe that the predicted target increases with the added value.
Analyzing the performance of the model for the overall test set, we can confirm the correlation between the model outputs and the ground truth since the correlation rate is around 77,5%. This model can be used for brightness correction or image quality assessment. In the next section, you will see some practical examples of where to use these models.
Once again, the model predictions were extracted for the original images (shown below). These predictions are also eloquent since the model returned positive values for the brightest images and negative values for the darkest ones, in particular, the coffee filter and the bridge pictures.
Use Cases
Self Supervised learning can be very useful to pre-train encoders to be used by other models or to be used as an extra task, making the final model more robust. However, there’s also a lot of potential for these models to be used directly as predictors, and here are a few examples of where to use them.
Healthcare
Image quality assessment for medical imaging – trivial models like a blur, brightness, and crop detectors help can assess image quality in real-time, being useful to select the sample to be analyzed (by another model or by an expert).
Real State
Image standardization in the website – brighter and more colorful images are more attractive to prospects and, taking pictures in poor lighting conditions can influence the propensity of engagement with the image. With a brightness model as the one proposed above, it is possible to assess this feature and correct it automatically.
Car Dealership
Similar to the previous use case, the pictures that show the product (the car, in this case) may influence the propensity of a user to become a buyer. Trivial computer vision models like brightness quantifiers and blur detectors can be used to filter which images have enough quality to be published on the website.
Conclusion
As we saw in this post, you don’t always need a large dataset to build a model that meets the needs of your business.
If you’re interested in making your company’s decisions data-driven but you’re not sure you have a data structure prepared for that, contact us at [email protected], and let’s discuss some ideas!
If you want to learn more about it, enroll to our course:
Top Business Intelligence Dashboard Examples for 2025
Jul 2, 2025 in
Technical
Discover key business intelligence dashboard examples to enhance your data insights. Explore trending dashboards for impactful decision-making in 2025.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.