The Foundation: What Makes Data Science Architecture Work
Effective data science projects need a solid architecture. Think of it as the backbone for everything data-related, from gathering raw data to delivering useful insights. This framework guides how data flows, gets processed, and ultimately gets used within your organization. Building this foundation right is key for efficiency, scalability, and keeping things secure.
Key Pillars of Data Science Architecture
A strong data science architecture rests on a few key pillars. Each one is crucial for the whole system to work smoothly. These interconnected parts work together to bring you valuable insights. Let’s break them down:
Data Storage: This is about picking the right storage solutions for different kinds of data – structured, semi-structured, or unstructured. Think data lakes, data warehouses, or specialized databases. Things like data volume, how fast it comes in, and how quickly you need to access it will guide your choices.
Processing Frameworks: These give you the tools and infrastructure for transforming and processing data. This could be anything from Apache Spark or Hadoop for large-scale processing to scripting languages like Python for more focused data manipulation.
Analytics Engines: This is where the real magic happens. Analytics engines help you pull out meaningful insights from your data. This might mean using machine learning algorithms, statistical models, or business intelligence platforms. It all depends on what you need to analyze.
Visualization Layer: Insights are great, but they need to be easy to understand. This layer focuses on presenting your findings clearly and concisely, usually with interactive dashboards, reports, and other visual tools.
Modern Architectures and the Data Explosion
The world of data architecture has changed a lot recently. We’ve moved from traditional data warehousing to more agile and adaptable systems. Why? The sheer amount of data we’re dealing with now. By 2025, the global data volume is expected to hit 175 zettabytes, with 97.2 zettabytes created every year. That’s a mind-blowing amount! Check out these stats for more. This massive data growth means our data science architectures need to handle these huge datasets effectively. It really influences what kind of solutions we need – things that can scale and handle even more data in the future.
Evaluating Your Current Architecture
If you’re looking to boost your data capabilities, you need to see if your current architecture is up to snuff. Can your infrastructure handle your growing analytical needs? Think about scalability, flexibility, and cost-effectiveness. A good architecture can adapt to changing business needs and the constantly evolving data world.
Building Blocks: The Components That Power Modern Systems
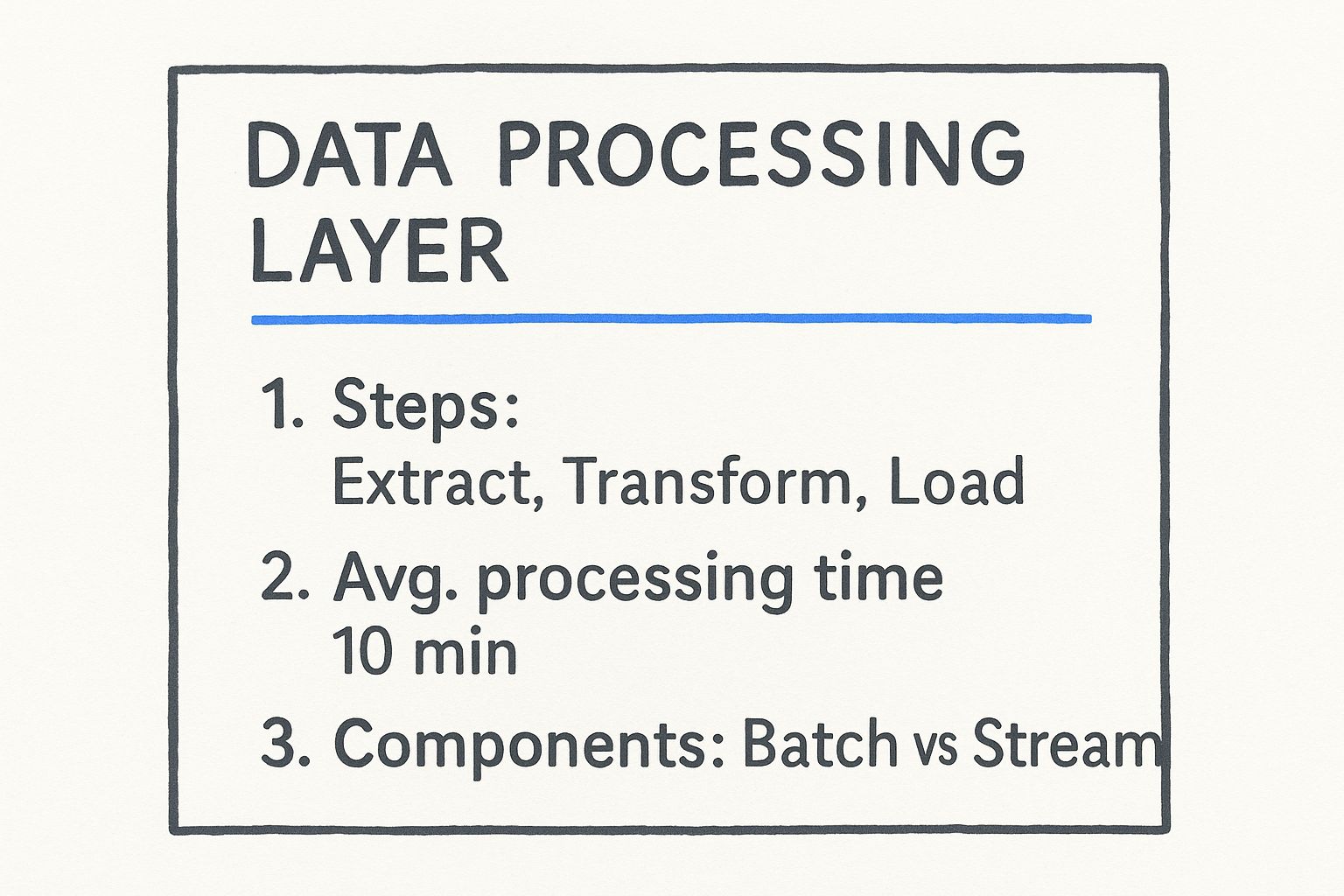
The infographic above gives us a cool visual of the data processing layer. It shows the Extract, Transform, Load (ETL) steps, the average 10-minute processing time, and how batch and stream processing fit in. As you can see, efficient data processing needs a smooth ETL process. You have to find the right balance between batch and stream processing. This depends on what your data science architecture actually needs. This balance is super important for getting the best performance. For example, real-time analytics might use stream processing a lot, while large-scale data transformations might do better with batch processing. Let’s take a closer look at what powers these systems.
Data Collection and Ingestion
This first step is all about grabbing raw data from different places. Think databases, APIs, streaming platforms, and even IoT devices. How you collect data depends on what kind of data it is and how fast it’s coming in. Data ingestion is also about getting the data ready for storage and processing. This often means cleaning, validating, and formatting the data. This makes sure everything is consistent and high-quality within your data science architecture.
Data Processing and Storage
Here’s where we turn raw data into something usable. This important step often uses the Extract, Transform, Load (ETL) process. This means pulling data from the source, changing it into a standard format, and putting it into its final destination. Different processing frameworks, like Apache Spark and Hadoop, are used depending on how much data you have and how complex it is. Picking the right storage – data lakes, data warehouses, or NoSQL databases – is also key for quick data retrieval and analysis in your data science architecture. Want to learn more about using processed data? Check out our guide on How to master data-driven decision making.
The following table provides a breakdown of the core components we’ve discussed so far, along with key technologies and considerations for each layer.
Core Components of Data Science Architecture
A comprehensive comparison of the essential layers in modern data science architecture
Architectural Layer
Key Technologies
Primary Function
Considerations
Data Collection & Ingestion
APIs, Databases, Streaming Platforms, IoT Devices
Gathering and preparing raw data from various sources
Data velocity, source systems, data quality, security
Data Processing & Storage
Apache Spark, Hadoop, Data Lakes, Data Warehouses, NoSQL Databases
Transforming and storing data in a usable format
Data volume, data complexity, storage efficiency
Analytics & Modeling
Statistical Modeling, Machine Learning Algorithms, Business Intelligence Tools
Extracting insights from processed data
Business objectives, data types, model deployment
Visualization & Reporting
Visualization tools and dashboards
Presenting insights in a clear and accessible manner
Target audience, report formats, data storytelling
This table highlights the interconnectedness of each layer and the technologies involved in building a robust data science architecture. From initial data collection to final reporting, each component plays a crucial role in extracting valuable insights.
Analytics and Modeling
This layer uses different techniques to get insights from the processed data. This might include statistical modeling, machine learning algorithms, and business intelligence tools. What you use depends on your business goals and the type of insights you’re looking for. Building and using models for predictive analytics and other applications are important parts of this layer of the data science architecture.
Visualization and Reporting
The last step is all about showing the insights you got from your analysis. This usually means using visualization tools and dashboards to communicate complex data in a way that’s easy to understand. Good visualizations are crucial for helping stakeholders understand and use the insights from your data science architecture. This includes making reports, dashboards, and interactive visualizations for different people in the organization. These reports are often customized for different stakeholders, giving them the right information to make decisions at different levels.
Scaling Up: Architectures That Grow With Your Business
As your data projects expand, your infrastructure needs to keep pace. This means your data science architecture has to handle increasing data volume, velocity, and variety without sacrificing speed. This section explores practical strategies for creating adaptable infrastructures that scale with your business. This adaptability is essential for meeting the growing demands of data-driven organizations.
Distributed Computing and Containerization
A core element of scaling is distributed computing, where tasks are spread across many machines. Frameworks like Apache Spark are great for this, allowing faster processing of massive datasets. Containerization tools like Docker package applications and their dependencies into portable units, making deployment and management across different environments much easier. Together, these technologies offer a flexible and scalable foundation for your data science architecture. When designing new systems, exploring different architectural approaches like decentralized data architectures is a smart move. This ensures your systems are future-proof and can integrate with emerging technologies.
Orchestration and Data Management
Managing these distributed containers requires orchestration tools like Kubernetes. Kubernetes automates the deployment, scaling, and management of containerized applications, optimizing resource use. For instance, if a task needs more resources, Kubernetes can automatically assign them. Further enhancing scalability are strategies like data partitioning, sharding, and replication. Data partitioning breaks data into smaller, manageable pieces, while sharding spreads these pieces across multiple servers. Replication creates data copies for redundancy and high availability. These techniques maintain performance even as your data explodes, a crucial part of a well-designed data science architecture.
Challenges of Scaling and Cloud Solutions
Scaling a data science architecture has its hurdles. Keeping data consistent across distributed systems is key. Efficient resource allocation is also vital, ensuring processing power is available when and where needed. Plus, controlling costs as your systems grow becomes a major factor. Cloud services offer adaptable answers to these issues. They provide on-demand resources and scalable infrastructure, allowing you to adjust to changing requirements without massive upfront costs. Deciding when to use cloud services versus on-premises infrastructure is a critical step in designing a sustainable and scalable data science architecture. For more insights, check out this article: How to master AI business solutions.
The need for skilled data scientists is rising, highlighting the importance of solid data infrastructures. Job postings requiring a data science degree have gone from 47% in 2024 to 70% in 2025, a 23% jump. This growth emphasizes why organizations need to invest in scalable data science architectures to support the growing demand for data-driven insights. You can find more detailed stats here.
Building a scalable data science architecture is an ongoing journey. By adopting distributed computing, containerization, intelligent data management techniques, and strategically using cloud solutions, your organization can create a powerful data infrastructure prepared for future growth and ready to unlock the full potential of its data.
Trust By Design: Governance in Data Science Architecture
A solid data science architecture isn’t just about raw processing power and being able to handle tons of data. It’s also about building trust. And to build trust, you need to bake in governance and security right from the start. This proactive approach keeps sensitive data safe while still letting innovation flourish. Think about managing data access, ensuring quality, and keeping everything compliant with the rules.
Data Cataloging and Access Controls
One of the first steps towards building trust? A data catalog. It’s basically a central inventory of all your data, so data professionals can easily find and understand what’s available. Like a library catalog for your data! It has descriptions, metadata, and lineage information. Pair that with strong access controls, and your data catalog ensures only the right people see sensitive info. This combo of discoverability and security sets the stage for responsible data use.
Audit Mechanisms and Regulatory Compliance
Trust also needs accountability. Solid audit mechanisms provide a record of who accessed or changed what data, allowing you to track data usage and spot potential security breaches. This transparency builds trust and helps you meet those pesky compliance requirements. And speaking of compliance, frameworks like GDPR and HIPAA have specific rules for handling data. Your architecture needs to make it easy to follow these rules without slowing down your data science team.
Data Lineage and Quality Monitoring
Knowing where your data comes from and how it’s been transformed is key for trusting your analytics. This is where data lineage tracking comes in. It provides a complete data history, from source to destination. This helps with debugging, auditing, and ensuring data accuracy. And then there’s data quality monitoring. By constantly checking for completeness, consistency, and accuracy, you can catch and fix data quality issues before they mess up your insights. This ongoing monitoring is essential for a trustworthy architecture.
For example, the explosion of IoT devices—predicted to hit 38.6 billion by 2025—really underscores the need for strong data management in data science architectures. Check out these stats. Managing and securing mountains of data from all sorts of sources is a growing challenge.
Balancing security and accessibility is a tough job for data science architects. Security is crucial, but too much restriction can slow down data professionals who need to get insights fast. A well-designed data science architecture supports both security and accessibility, empowering data professionals while protecting sensitive info. This means smart planning and using the right tools and processes for secure yet efficient data access. With these strategies, organizations can build a data science architecture that not only fuels innovation but also fosters trust and ensures responsible data use. The result? More reliable insights and smarter business decisions.
AI-Ready Architecture: Integrating Machine Learning at Scale
Building a data science architecture that handles basic analytics is great, but creating a system that’s truly ready for the future means thinking bigger. It needs to handle the heavy lifting of AI and machine learning (ML). This means building an architecture that smoothly blends these powerful tools into your current data setup. This integration is how you unlock the real power of your data.
Specialized Infrastructure for Machine Learning
Machine learning has its own unique infrastructure needs. Model training, for example, often needs serious computing power to chew through massive datasets and complex algorithms. Good feature management is essential for picking and prepping the right data to feed your models. You’ll also want model versioning to keep track of different model iterations, so you can easily go back to older versions or compare performance. Finally, solid deployment pipelines automate the process of getting models from development to production – so you can get your ML models working faster. Each of these pieces needs careful thought when designing your data science architecture.
Designing for the Entire ML Lifecycle
A successful data science architecture needs to support the whole ML lifecycle. This covers everything from prepping data and training models to deployment, monitoring, and constant improvement. This big-picture approach helps avoid common problems, like models that never leave the lab or go unused because they’re hard to deploy. Imagine a factory making amazing products but with no way to ship them—that’s what happens with under-utilized ML models. Designing for the entire lifecycle makes sure your models deliver real business value. Want to dive deeper? Check out this guide on How to master machine learning for business analytics.
Monitoring and Continuous Improvement
Once your ML models are up and running, they need regular check-ups. Model performance can slip over time because the data changes, or the environment shifts. This is why your data science architecture needs to make continuous improvement easy. This means regularly checking model performance, retraining models with fresh data, and tweaking things as needed. Solid data governance is key for trust and compliance – this data governance framework template might be helpful. This iterative process keeps your models accurate and effective, even when things change. Think of a model predicting customer churn – it’ll need retraining as customer behavior changes.
Emerging Paradigms and Organizational Readiness
New approaches like AutoML, federated learning, and edge AI are changing the game in machine learning. AutoML automates parts of model development, while federated learning lets you train models on data spread across different locations without sharing sensitive info. Edge AI brings computation and storage closer to where the data comes from, reducing lag and bandwidth needs. Figuring out how these new technologies fit your needs and organizational readiness is key to building a truly future-proof data science architecture. This highlights the importance of architectures that can handle complex analytics and work with AI technologies. The global AI market is expected to hit $190.61 billion by 2025, showing the growing need for AI-powered data science architectures. Learn more about the booming AI market here. By understanding how machine learning is changing, you can create a data science architecture that’s ready for today and tomorrow.
The following table summarizes different approaches to integrating AI/ML into your data science architecture:
AI/ML Integration Approaches in Data Science Architecture
Integration Approach
Architectural Impact
Benefits
Challenges
Ideal Use Cases
Direct Integration
Significant changes to existing systems may be required.
Tight coupling, improved performance.
Integration complexity, potential vendor lock-in.
Applications requiring real-time ML predictions, such as fraud detection.
API-Based Integration
Minimal changes to existing architecture.
Flexibility, ease of integration.
Potential performance overhead, dependency on API availability.
Integrating pre-trained models or cloud-based AI services into existing applications.
Hybrid Approach
Combines direct and API-based integration.
Balances performance and flexibility.
Increased complexity in managing different integration methods.
Organizations with diverse ML needs and existing infrastructure.
Key takeaways from the table include the trade-offs between performance and flexibility when choosing an integration approach, and the importance of considering your organization’s specific use cases and existing infrastructure.
Next-Gen Architecture: What’s Coming in Data Science
The world of data science architecture is constantly evolving. Keeping up with the latest trends is key to building robust and future-proof data systems. It’s all about anticipating what’s next, not just reacting to the current state of things.
Decentralized Models: Data Mesh and Data Fabric
Many big players are shifting towards decentralized data models like data mesh and data fabric. Think of a data mesh as treating data like a product. Different teams own and manage their specific data domains, distributing responsibility and making data more readily available. A data fabric, however, connects various data sources, creating a single, unified view. It’s the connective tissue of your data ecosystem. Understanding these decentralized approaches is essential for the future of your data science architecture.
The Rise of Real-Time and Edge Computing
Real-time analytics and edge computing are changing how we handle data. Serverless analytics dynamically scales resources, cutting down on infrastructure management headaches. Edge computing processes data closer to the source, minimizing latency and bandwidth issues. These technologies are crucial for applications needing instant insights, such as fraud detection or real-time equipment monitoring. Your data science architecture needs to be ready to incorporate these capabilities.
Evaluating Emerging Technologies
The data science world is full of exciting (and sometimes confusing) new terms. It’s important to know what’s truly groundbreaking and what’s just hype. Graph databases, for example, excel at showing relationships between data points, opening up unique analytical possibilities. Composable analytics lets you build modular and reusable analytical components, speeding up development. Augmented intelligence combines human expertise with the power of AI for smarter decisions. But remember, not every new technology is the right fit for everyone. Careful evaluation is key to building an effective data science architecture. Plus, the big data analytics market is booming, projected to reach $655 billion by 2029. This growth is fueled by the increasing demand for advanced analytics platforms. Learn more about the growing market here.
By understanding these trends and embracing the future of data science architecture, you can build data systems that are not only efficient today but also ready for tomorrow’s challenges and opportunities. Choose the right technologies that align with your long-term goals and build a system that can adapt and grow.
Ready to harness the power of AI for your business? NILG.AI offers custom AI solutions designed to streamline processes, boost growth, and unlock valuable insights from your data. Visit us today to explore how we can help you reach your business goals.
Master customer retention rate calculation with this practical guide. Learn the formulas, see real-world examples, and get actionable tips for business growth.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.