Bad data costs businesses real money and lost opportunities. This listicle cuts straight to the chase, outlining eight common data quality issues impacting your bottom line, from inaccurate insights to operational inefficiencies. We’ll cover data completeness, accuracy, consistency, duplication, timeliness, validity, integration, and lineage – giving you actionable insights to improve your data, and your business. Ignoring these data quality issues puts you at a disadvantage, so let’s dive in.
1. Data Completeness
Data completeness, a cornerstone of robust data quality, refers to the extent to which all required data is present within a dataset. Think of it like baking a cake: if you’re missing key ingredients like flour or eggs, the end result will be far from satisfactory. Similarly, missing values, empty fields, or absent records in your data can significantly impact the quality of your analysis and lead to flawed business decisions. This issue often crops up when data collection processes fail to capture all the necessary information, or when data gets lost somewhere along the way, perhaps during transfer or storage. Imagine trying to analyze customer behavior with incomplete purchase histories – you’d be missing a crucial piece of the puzzle. This is why addressing data completeness is crucial for any organization relying on data for informed decision-making.
This issue manifests in several ways. You might find missing values in critical fields, such as customer addresses or product prices. Incomplete records or rows can also be a problem, where some data points for a specific entity are present, but others are absent. In time series data, absent data points can disrupt trend analysis and forecasting. Databases often suffer from null or empty fields, hindering accurate querying and reporting. Finally, when dealing with multiple data sources, partial data capture can lead to a fragmented and incomplete picture. For instance, a company might have customer purchase data from its online store but lack information about their in-store interactions, leading to an incomplete understanding of customer behavior.
So, why does data completeness deserve a top spot on the list of data quality issues? Quite simply, its impact is pervasive. Incomplete data can lead to biased analysis and incorrect conclusions, potentially costing your business significant time and resources. Imagine launching a targeted marketing campaign based on incomplete customer demographics – you’d likely miss a large segment of your target audience.
However, the good news is that data completeness is often relatively easy to identify and measure using various statistical tools. Plus, there are techniques like data imputation that can help fill in the gaps, although it’s important to remember that these methods can introduce their own biases. Furthermore, addressing data completeness issues often has a clear and immediate positive impact on business operations, leading to better decision-making and more efficient processes.
Let’s look at some real-world examples. Netflix tackles missing user preference data by using sophisticated recommendation algorithms. Healthcare systems implement mandatory field validation at the point of data entry to ensure complete patient records. E-commerce platforms leverage progressive profiling, gradually collecting complete customer information over time, enhancing their understanding of customer needs and preferences.
Now, how can you improve data completeness in your organization? Here are some practical tips:
Implement data validation rules at the point of entry: This prevents incomplete or inaccurate data from entering your systems in the first place. Think of it as a gatekeeper ensuring only high-quality data gets through.
Use progressive data collection strategies: Don’t overwhelm users with lengthy forms. Collect essential information upfront and gradually gather more details as the relationship develops.
Establish data quality metrics and monitoring dashboards: Track key indicators of data completeness and proactively identify potential issues.
Consider the business impact: Sometimes, the cost of collecting missing data might outweigh the benefits. In such cases, imputation or other workaround strategies might be more appropriate. Weigh your options carefully.
Data completeness is a critical aspect of data quality. By understanding the challenges and implementing the right strategies, organizations can significantly improve the reliability and value of their data, ultimately leading to better business outcomes. From accurate reporting and analysis to effective decision-making, the benefits of complete data are undeniable. So, take the time to assess your data completeness and take action to improve it. Your business will thank you for it.
2. Data Accuracy
Data accuracy, arguably the most critical dimension of data quality, refers to how closely data values reflect the true or correct values they represent. Think of it like hitting the bullseye on a dartboard – the closer your data is to the truth, the higher its accuracy. Inaccurate data, stemming from sources like human error, system glitches, or simply outdated information, can lead to flawed insights and ultimately, poor business decisions. You wouldn’t want to base a crucial marketing campaign on outdated customer demographics, would you? Accurate data is the bedrock of sound analysis and reporting, making it essential for any data-driven organization.
So, what does inaccurate data look like in the real world? It can manifest as incorrect values lurking within your datasets, outdated information that no longer reflects current reality, typos and input errors from manual data entry, system calculation errors, or even issues with the precision of your measurements. For instance, imagine a customer database with incorrect addresses – this seemingly small error can lead to wasted marketing materials, failed deliveries, and frustrated customers. Or consider a financial institution relying on inaccurate transaction data – this could result in erroneous financial reports, missed opportunities for fraud detection, and potentially significant financial losses.
The benefits of maintaining high data accuracy are numerous. Accurate data empowers confident decision-making, allowing businesses to develop strategies based on a solid foundation of truth. It also builds trust with stakeholders, demonstrating a commitment to reliable information and transparency. Moreover, high accuracy reduces costs associated with correcting mistakes down the line, saving valuable time and resources. Think of it as an investment that pays off in the long run.
However, achieving and maintaining high data accuracy isn’t a walk in the park. It can be expensive and time-consuming, requiring rigorous verification and maintenance processes. You might need to consult multiple data sources for cross-validation, adding complexity to the process. And depending on the specific use case, defining accuracy can sometimes be subjective. What constitutes “accurate enough” for one purpose might not be sufficient for another.
Despite these challenges, the payoff of accurate data far outweighs the costs. Companies that prioritize data accuracy gain a significant competitive edge. For example, Amazon’s address verification system minimizes delivery errors, enhancing customer satisfaction and operational efficiency. Financial institutions leverage real-time fraud detection systems to maintain transaction accuracy and protect their customers. And Google Maps continuously updates its location data through crowdsourcing and satellite imagery, ensuring users have access to the most accurate navigational information. These are just a few examples of how businesses across various industries are leveraging data accuracy to improve their operations and drive success.
So, how can you improve data accuracy within your own organization? Here are some actionable tips:
Implement real-time data validation and verification processes: Catch errors as they occur, preventing them from spreading throughout your systems.
Use multiple data sources for cross-validation: Compare data from different sources to identify discrepancies and improve overall accuracy.
Establish clear data stewardship roles and responsibilities: Assign ownership and accountability for data quality within your organization.
Implement regular auditing and cleansing procedures: Periodically review and clean your data to remove errors and maintain accuracy over time.
Invest in automated data quality monitoring tools: Leverage technology to automate data quality checks and identify potential issues proactively.
These steps can help you build a robust data quality framework and ensure your data is as accurate as possible. Whether you’re a business executive, data scientist, operations manager, or entrepreneur, understanding and prioritizing data accuracy is crucial for success in today’s data-driven world. You can learn more about Data Accuracy to further deepen your understanding of this critical aspect of data quality. Addressing data quality issues, especially concerning accuracy, is a continuous process, but one that yields substantial rewards. By implementing these strategies, you can ensure your organization makes decisions based on reliable information, leading to better outcomes and a stronger bottom line.
3. Data Consistency: The Glue That Holds Your Data Together
Data consistency, it’s kind of a big deal when we’re talking about data quality issues. Think of it as the glue that holds your data together. It makes sure that your data values are uniform and coherent, no matter where they live – whether it’s across different systems, databases, or even across different time periods. Without data consistency, you’re looking at a tangled mess of information that’s hard to understand and even harder to use. This can lead to all sorts of headaches, from inaccurate reporting to flawed business decisions. So, why is data consistency worthy of a spot on the data quality issues list? Simply put, it’s foundational to everything else. You can’t build a reliable house on a shaky foundation, and the same applies to your data.
Inconsistent data happens when the same information looks different in various sources. Maybe your customer database lists “St.” for street while your shipping system uses “Street.” Or perhaps your sales team tracks revenue in US dollars, but your finance department uses Euros. These might seem like small discrepancies, but they can quickly snowball into major problems, especially as your organization grows. Imagine trying to analyze customer behavior when you have fragmented, contradictory information about who they are and what they’ve purchased. It’s like trying to assemble a jigsaw puzzle with pieces from different puzzles – frustrating and ultimately fruitless. Some common features of data inconsistency include varying data formats and types, different naming conventions for the same things (like customers or products), inconsistencies in units of measurement, and even conflicting data values for the same entity.
Now, let’s talk about the good stuff. Consistent data unlocks a ton of benefits. It allows for seamless data integration across all your systems, so you can get a single, unified view of your business. It reduces confusion and misinterpretation, so everyone’s working from the same page. And it makes it much easier to automate data processing, freeing up your teams for more strategic work. Think about it: automated reports, streamlined workflows, data-driven insights readily available – all thanks to consistent data.
However, achieving and maintaining data consistency isn’t a walk in the park. It requires a concerted effort, especially if you’re dealing with legacy systems that weren’t designed for integration. You’ll likely need ongoing governance to make sure everyone sticks to the new standards. And things can get particularly complex in multi-vendor environments where different systems have their own quirks and conventions. But don’t worry, the benefits far outweigh the challenges.
So, what can you do to improve data consistency? Here are a few actionable tips:
Establish data governance policies and standards: Create clear guidelines for how data should be collected, stored, and used across your organization. Think of it as the rulebook for your data.
Implement Master Data Management (MDM) solutions: MDM tools help you create a single, “golden record” for key entities like customers and products, ensuring consistency across all systems. Salesforce, for example, offers robust MDM capabilities.
Use data mapping and transformation tools: These tools help you convert data from different sources into a consistent format, bridging the gaps between disparate systems.
Create and maintain data dictionaries: A data dictionary acts as a central repository of information about your data, defining terms, formats, and relationships.
Regular data profiling to identify inconsistencies: Data profiling helps you uncover inconsistencies and anomalies in your data, so you can address them proactively.
Real-world examples of successful data consistency implementation are plentiful. Banks, for instance, are standardizing customer data formats across different product lines to provide a seamless customer experience. Healthcare systems are increasingly adopting HL7 standards to ensure consistent patient data exchange between hospitals and clinics. And companies like Salesforce are leveraging MDM to maintain a single, accurate view of their customers.
When should you focus on data consistency? The answer is: yesterday! Seriously, data consistency isn’t something you can afford to ignore. Whether you’re a startup or a Fortune 500 company, data consistency is crucial for making informed decisions, improving operational efficiency, and gaining a competitive edge. By prioritizing data consistency, you’re investing in the long-term health and success of your organization.
4. Data Duplication
Data duplication, a common data quality issue, is like having multiple copies of the same photo cluttering up your phone’s storage. It occurs when identical or nearly identical information appears multiple times within a single dataset, or even across different systems within your organization. Think of it as redundant entries taking up valuable space and creating confusion. This seemingly innocuous issue can lead to a cascade of problems, impacting everything from your bottom line to your customer’s experience. It definitely earns its spot on the list of critical data quality issues that need your attention.
How does this happen? Well, data duplication can arise from a variety of sources. Imagine different departments independently collecting customer information, leading to multiple profiles for the same person. Or perhaps you’ve recently migrated data from legacy systems, inadvertently creating duplicates in the process. Manual data entry, with its inherent potential for human error, is another prime culprit. Features of data duplication include exact duplicate records scattered across different systems, near-duplicate records with slight variations (like a misspelled name or a slightly different address), multiple customer profiles for the same individual, redundant entries stemming from multiple data sources, and, as mentioned earlier, legacy system integration woes.
The consequences can be far-reaching. Think inflated storage costs and sluggish system performance. More importantly, duplicated data can skew your analytics and reporting, leading to faulty business decisions. Imagine trying to forecast sales based on inflated customer numbers or misallocating marketing resources due to inaccurate demographic data – ouch! From an operational standpoint, duplicates can create a frustrating customer experience, with customers receiving multiple, identical communications. It also increases the maintenance overhead for your IT and data teams.
However, there’s a silver lining. Sometimes, the presence of duplicates can actually help validate data through comparison. For instance, if two records are almost identical, it might indicate a high probability of accuracy. Similarly, duplicated data can sometimes highlight popular or frequently accessed information.
Despite these minor advantages, the downsides of data duplication significantly outweigh the pros. Incorrect analytics and reporting can lead to misguided business strategies and lost revenue. Think about a financial report that double-counts sales due to duplicate entries – not a scenario any business executive wants to encounter. Similarly, a poor customer experience, fueled by redundant communications, can damage your brand reputation and erode customer loyalty.
Several real-world examples showcase the importance of tackling data duplication. Expedia, the popular travel booking platform, grapples with duplicate hotel listings due to variations in names and addresses. They employ fuzzy matching algorithms – essentially sophisticated search techniques – to identify and merge these duplicates, ensuring a seamless user experience. Similarly, LinkedIn uses duplicate profile detection to maintain the integrity of its professional network. Credit reporting agencies also utilize advanced matching algorithms to consolidate consumer records and ensure accurate credit histories.
So, what can you do to combat this data quality menace? Thankfully, several actionable steps can help. Implement data deduplication algorithms, especially those using fuzzy matching. This technique allows you to identify near-duplicates even when the data isn’t perfectly identical. Establishing unique identifiers and primary keys for each record is crucial. This helps prevent duplicates from being created in the first place. For near-duplicates, probabilistic matching techniques can be incredibly effective. Regular data cleansing and merge processes should become routine procedures to catch and eliminate duplicates before they wreak havoc. And perhaps most importantly, implement data entry controls at the source to minimize the introduction of duplicates from the get-go.
For business executives and decision-makers, understanding the impact of data duplication on strategic planning and resource allocation is vital. IT and data science teams need to be equipped with the right tools and techniques to implement effective deduplication strategies. Operations and process managers should focus on refining data entry processes and implementing preventative measures. For corporate training and HR leaders, educating staff about data quality best practices is key. Even entrepreneurs and startup innovators should prioritize data quality from the outset to avoid costly cleanup efforts down the road.
Addressing data duplication is not a one-time fix, but rather an ongoing process. By implementing the right strategies and tools, you can ensure the accuracy and reliability of your data, leading to better business decisions, improved operational efficiency, and a happier customer base. This proactive approach is essential for any organization striving for data-driven success in today’s competitive landscape.
5. Data Timeliness
In today’s fast-paced business world, having access to the right data is crucial, but equally important is having it when you need it. This is where data timeliness comes in. It’s a key aspect of data quality that refers to how current and readily available your data is. Think of it like this: using yesterday’s weather forecast to plan today’s picnic – not very helpful, right? Similarly, outdated or delayed data can lead to poor decisions, missed opportunities, and ultimately, impact your bottom line. This makes data timeliness a critical data quality issue, especially for businesses in dynamic sectors like finance, e-commerce, and social media.
Imagine trying to make stock trades based on last week’s market data. You’d likely lose your shirt! In these fast-moving environments, real-time insights are the key to staying competitive. Data timeliness is all about ensuring your data reflects the current state of affairs, allowing you to make informed decisions and react quickly to market changes.
So, how does data timeliness work in practice? It involves a combination of factors, including:
Efficient data processing: This means getting data from its source to your decision-makers as quickly as possible. Delays in processing, whether due to outdated systems or inefficient pipelines, can significantly impact timeliness.
Frequent updates: Depending on your needs, this could range from real-time streaming to daily or weekly updates. The frequency should align with the speed at which the real-world situation changes. Think about a social media platform. They need up-to-the-second updates to reflect trending topics and user activity.
Synchronization across sources: If you’re pulling data from multiple sources, it’s critical that they’re all synced to the same timeframe. Imagine having sales data from last week combined with inventory data from yesterday – you’d get a skewed picture of your current stock levels.
Addressing time zones: In a globalized world, time zone differences can wreak havoc on data timeliness. Ensure your data is appropriately timestamped and converted to a consistent time zone to avoid confusion.
Several features can indicate problems with data timeliness. These include outdated information that no longer reflects current reality, delayed data processing leading to slow availability, inconsistent update frequencies across different data sources, batch processing delays in real-time environments, and time zone or temporal synchronization issues.
There are some fantastic examples of businesses successfully leveraging real-time data. Uber, for instance, uses real-time data for pricing adjustments based on demand and driver location updates, providing both riders and drivers with the most up-to-date information. Stock trading platforms rely on millisecond-level market data updates to facilitate timely trades. Netflix’s recommendation engine uses your current viewing behavior to suggest what you might enjoy watching next. And think about weather services providing minute-by-minute forecast updates to help you decide if you need that umbrella. These businesses understand the value of timely data and have invested heavily in systems to support it.
So, how can you improve data timeliness within your organization? Here are a few actionable tips:
Implement real-time data streaming: Where business decisions are highly time-sensitive, consider investing in real-time data streaming technologies. This is especially crucial in areas like fraud detection, personalized marketing, and supply chain management.
Establish data freshness requirements: Don’t adopt a one-size-fits-all approach. Determine how current your data needs to be for different use cases. For strategic planning, weekly data might suffice, but operational decisions might require hourly or even real-time data.
Use change data capture (CDC): CDC allows you to track only the changes in your data, rather than replicating the entire dataset. This significantly reduces processing time and improves data freshness.
Monitor data latency: Set up automated alerts to notify you of any delays in data processing or availability. This allows you to proactively address issues before they impact business operations.
Balance timeliness with costs: While real-time data is powerful, it can also be expensive to implement and maintain. Carefully weigh the benefits against the costs and choose the approach that best suits your needs and budget. Sometimes near real-time is good enough and far less resource-intensive.
The benefits of timely data are undeniable. It empowers you to make better decisions, react faster to market changes, and improve customer experiences. However, implementing real-time systems can be costly and require significant infrastructure investment. There’s also the risk of prioritizing speed over accuracy, potentially compromising data quality. Therefore, it’s essential to carefully assess your requirements and find the right balance between timeliness and other data quality factors.
6. Data Validity and Format Issues
Data validity and format issues are a common headache when it comes to data quality. Think of it like this: you’re baking a cake, and the recipe calls for a cup of flour. You accidentally grab a cup of salt instead. The cake won’t turn out right, will it? Similarly, when data doesn’t adhere to the expected format or rules, it throws a wrench in the works, leading to all sorts of problems down the line. This particular data quality issue deserves its place on the list because its impact can range from minor inconveniences to major system failures, impacting business operations and decision-making.
Essentially, data validity issues crop up when the data you’re working with doesn’t play by the rules. These “rules” can be anything from specific formats (like dates, phone numbers, or email addresses) to acceptable value ranges (like a person’s age not being negative) or even complex business logic constraints (like ensuring an order total matches the sum of its items). These problems often stem from inadequate data entry controls, hiccups in system integration, or a lack of standardized data governance – basically, anything that lets bad data slip through the cracks.
Let’s dive into some specific features that characterize validity and format problems:
Invalid data formats: Imagine a database storing dates as “12-25-2024” in one entry and “2024/12/25” in another. This inconsistency makes analysis and reporting a nightmare. Similarly, incorrectly formatted phone numbers or email addresses can hinder communication and marketing efforts.
Values outside acceptable business ranges: A customer’s age recorded as 200 is clearly an error. Similarly, a product price of $0 or a negative quantity in an order indicates a data validity problem that needs attention.
Wrong data types in database fields: Storing a text string in a field designed for numerical values can cause calculations to fail and generate inaccurate reports. This can have serious consequences, especially when dealing with financial or scientific data.
Non-conforming text patterns and structures: Inconsistencies in how free-text fields are populated (e.g., variations in capitalization, abbreviations, or punctuation) can make it difficult to search, analyze, and interpret the data.
Violation of business rule constraints: Imagine a system allowing a customer to order a discontinued product or exceed their credit limit. These violations, stemming from inadequate data validation against business rules, can lead to operational chaos and financial losses.
Now, the good news is that these issues are often detectable through automated validation rules. Think of these rules as gatekeepers, preventing bad data from entering your systems in the first place. And with clear business rules in place, fixing these issues becomes relatively straightforward.
However, if left unchecked, these seemingly small issues can snowball into significant problems. They can cause system crashes, processing errors, and inaccurate reporting. Worse still, they can propagate through downstream systems, corrupting data across the entire organization. Cleaning up this mess often requires extensive manual review and correction, a time-consuming and costly process.
So, how do you prevent these issues? Here are some actionable tips:
Implement data validation rules at input points: Stop bad data at the source by enforcing format and value constraints during data entry. For example, an e-commerce site can implement email format validation during user registration, preventing typos and ensuring consistent data quality.
Use regular expressions for pattern matching: Regular expressions are powerful tools for validating complex text patterns, such as phone numbers, zip codes, and credit card numbers.
Establish data type constraints in databases: Define the correct data type for each field in your database (e.g., integer, text, date) to prevent incompatible data from being stored.
Create comprehensive data validation frameworks: Establish a structured approach to data validation, encompassing all data sources and business rules.
Provide user-friendly error messages and guidance: When data validation fails, provide clear and helpful error messages to guide users towards correcting the input.
Real-world examples of successful implementation include e-commerce sites validating email formats during registration, banking systems validating account numbers using check digit algorithms, healthcare systems ensuring medical codes conform to ICD-10 standards, and tax software validating Social Security Number formats.
Addressing data validity and format issues is crucial for maintaining data quality. By implementing the right strategies and tools, businesses can avoid the costly consequences of bad data and ensure their data is reliable, consistent, and fit for its intended purpose. It’s like making sure you have all the right ingredients and measurements before you start baking that cake – ensuring a successful outcome every time.
7. Data Integration and Synchronization Issues
Data integration and synchronization issues are a major source of data quality issues, especially as organizations increasingly rely on a patchwork of different systems. Think about it: you’ve got your CRM, your marketing automation platform, your sales database, maybe even some legacy systems hanging around. Getting all that data to play nicely together is a huge challenge, and when it goes wrong, it can seriously mess up your insights and decision-making. This is why addressing data integration and synchronization issues is crucial for maintaining high data quality.
These issues crop up when you’re trying to combine data from multiple sources. This could be anything from merging databases after a company acquisition to simply trying to get a consistent view of customer data across different departments. Common problems include schema mismatches (where the structure of the data is different across systems), varying data formats (like dates formatted differently), timing synchronization issues (leading to outdated information), and conflicting data values (where different systems have different records for the same entity). If you’re dealing with large datasets, things like Extract, Transform, Load (ETL) processes can also fail, further complicating the integration process.
Imagine a retail giant like Walmart trying to manage inventory across thousands of stores, both physical and online. Getting real-time inventory updates is crucial for their operations. If their data integration is flawed, they could end up overstocked in some locations and out of stock in others, leading to lost sales and unhappy customers. On the other hand, successful data integration enables powerful cross-system analytics. For instance, a healthcare system can integrate patient records from various hospitals and clinics, providing a holistic view of a patient’s medical history and enabling better diagnoses and treatment plans.
Several strategies can help you tackle these data integration challenges. Implementing a robust ETL process with proper error handling is essential. Think of ETL as the cleaning crew for your data, making sure everything is formatted and structured correctly before it enters your data warehouse. Establishing clear data mapping and transformation standards ensures consistency. Using an Enterprise Service Bus (ESB) can facilitate smoother system integration. And where possible, API-first integration approaches offer flexibility and scalability. Thorough integration testing is also crucial to catch any problems early on.
While getting data integration right can be complex and expensive, requiring ongoing maintenance and monitoring, the benefits are undeniable. Successful integration provides comprehensive data views, enabling cross-system analytics and reporting that supports critical digital transformation initiatives. The downside is that poorly managed integration can actually introduce new data quality issues during the transformation process, so careful planning and execution are vital.
Experts like Ralph Kimball, known for his work on data warehousing, and Bill Inmon, a pioneer in data warehouse architecture, have emphasized the importance of robust data integration. Industry analyst firms like Gartner have also highlighted best practices and concepts related to integration platforms.
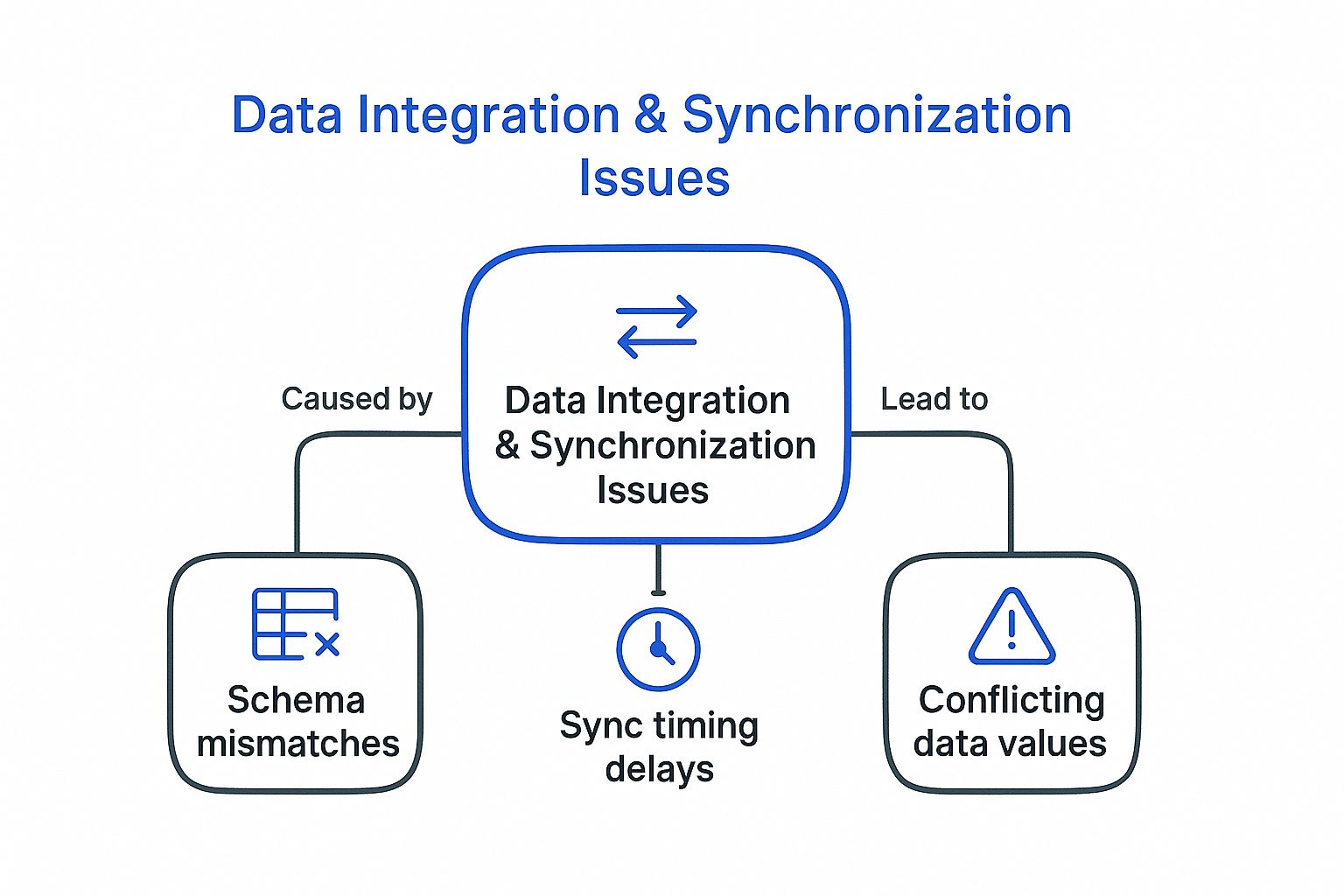
The following infographic visualizes the core challenges of data integration, highlighting the interconnectedness of schema mismatches, synchronization timing delays, and conflicting data values:
As the infographic illustrates, these three core challenges are intricately linked and can exacerbate data quality issues if not addressed proactively. For instance, a schema mismatch can lead to incorrect data mapping, ultimately resulting in conflicting data values. Similarly, synchronization timing delays can compound the problem of conflicting data by introducing outdated information into the mix.
Learn more about Data Integration and Synchronization Issues This article delves deeper into the practical implications of managing changing data sources, a common challenge in data integration. Understanding these challenges and implementing the right strategies will help you avoid the headaches of poor data quality and unlock the true potential of your data.
8. Data Lineage and Traceability Issues
Data lineage and traceability, or knowing where your data comes from and where it goes, is a crucial aspect of maintaining high data quality. Think of it like a detective investigating a crime scene. They need to trace every piece of evidence back to its source to understand the full story. Similarly, in the business world, understanding the complete journey of your data is essential for identifying and resolving data quality issues, ensuring compliance, and making sound, data-driven decisions. If you’re struggling with data quality issues, tackling lineage and traceability might be the game-changer you need.
Simply put, data lineage maps the entire lifecycle of your data. It tells you where the data originated, what processes it went through, and where it finally ends up. Traceability, on the other hand, refers to the ability to track data back to its source at any point in its journey. Without clear lineage and traceability, you’re essentially flying blind, relying on data that might be inaccurate, incomplete, or simply untrustworthy. This can lead to flawed insights, poor decision-making, and even regulatory penalties.
Imagine you’re a bank relying on customer data to assess credit risk. If you don’t know the origin and transformation history of that data, how can you be confident in its accuracy? Maybe the data was incorrectly entered initially, or perhaps it was modified during a system migration without proper documentation. Without a clear lineage, these errors can go unnoticed, leading to inaccurate risk assessments and potentially significant financial losses. This is just one example of why data lineage and traceability are critical for maintaining data quality and minimizing potential risks.
Here are some common characteristics of poor data lineage and traceability that contribute to broader data quality issues:
Unknown data sources and origins: Not knowing where your data comes from is a major red flag. It makes it impossible to verify its accuracy or assess its reliability.
Undocumented data transformations and processing steps: If you don’t know how your data has been manipulated, aggregated, or transformed, you can’t understand its current state or trust its integrity.
Missing audit trails for data changes: Without a clear record of who made changes to the data and when, it becomes incredibly difficult to pinpoint the source of errors or inconsistencies.
Inability to trace data quality issues to root causes: Identifying and resolving data quality issues becomes a guessing game when you lack the ability to trace the data back to its origins.
Lack of impact analysis for system changes: Without understanding data dependencies, implementing system changes can have unintended consequences, leading to data corruption or inconsistencies.
Pros and Cons of Implementing Data Lineage and Traceability:
Like any significant undertaking, establishing robust data lineage and traceability has both advantages and disadvantages. Understanding these trade-offs can help you determine the best approach for your organization.
Pros:
Quick issue resolution: Clear lineage enables faster identification and resolution of data quality problems, minimizing their impact.
Regulatory compliance and auditing: Strong lineage is essential for complying with data governance regulations like GDPR, CCPA, and industry-specific mandates like Basel III in finance.
Confidence in data accuracy and reliability: Knowing the origin and transformation of your data builds trust in its accuracy, leading to better decision-making.
Facilitates impact analysis for system changes: Lineage information helps predict the impact of system changes, reducing the risk of unintended consequences.
Cons:
Expensive and complex to implement comprehensively: Building a comprehensive lineage system can be a significant investment in terms of time, resources, and technology.
Requires significant ongoing maintenance: Keeping lineage information up-to-date requires continuous effort and dedicated resources.
May require retrofitting existing systems: Integrating lineage tracking into legacy systems can be challenging and may require substantial modifications.
Real-World Examples and Actionable Tips:
Several organizations have successfully implemented data lineage and traceability to improve their data quality and gain a competitive edge. For instance, banks leverage data lineage for regulatory compliance with Basel III and GDPR, while pharmaceutical companies use it to track clinical trial data for FDA submissions. Even Netflix uses lineage tracking to optimize its content recommendation algorithms.
Here are some practical tips for implementing data lineage and traceability in your organization:
Implement automated data lineage capture tools: Invest in tools that automatically capture and document data lineage information.
Document all data transformation processes: Maintain detailed documentation of every step in your data pipelines, including transformations, aggregations, and validations.
Use metadata management platforms: Leverage metadata management platforms to store and manage lineage information effectively.
Establish data governance frameworks with lineage requirements: Incorporate data lineage as a core component of your data governance strategy.
Regular auditing and validation of lineage information: Perform regular audits to ensure the accuracy and completeness of your lineage information.
Implementing proper data lineage and traceability is not a quick fix, but rather a strategic investment in the long-term health of your data. It empowers you to build trust in your data, improve decision-making, and meet regulatory requirements. By understanding the importance of data lineage and taking actionable steps to improve it, you can significantly enhance the quality of your data and unlock its full potential.
8 Key Data Quality Issues Comparison
Issue
Implementation Complexity 🔄
Resource Requirements ⚡
Expected Outcomes 📊
Ideal Use Cases 💡
Key Advantages ⭐
Data Completeness
Moderate – requires improving collection and validation processes
Moderate – may involve data imputation and enhanced capture methods
Improved analysis accuracy and decision-making
Missing data scenarios, multi-source data collection
Easy to detect and measure; clear business impact
Data Accuracy
High – needs continuous verification and validation
High – involves multiple validation sources and auditing
High confidence in decisions; trusted data
Applications requiring precise and reliable data
Builds trust; reduces correction costs
Data Consistency
High – needs standardization across systems
Moderate to High – governance and tools needed
Uniform data enabling seamless integration
Multi-system environments, cross-system reporting
Enables automated processing; reduces confusion
Data Duplication
Moderate – deduplication algorithms and controls
Moderate – requires dedupe tools and monitoring
Reduced storage & improved accuracy
Customer data management, CRM, marketing databases
Can validate data presence; identifies popular data
Data Timeliness
High – real-time infrastructure implementation
High – fast processing systems and monitoring
Timely decisions, competitive advantage
Real-time analytics, financial trading, IoT
Supports real-time personalization and alerts
Data Validity and Format Issues
Moderate – input controls and validation rules
Low to Moderate – automated validation often possible
Reduced errors and data processing failures
Systems with strict format requirements
Preventable via automation; straightforward fixes
Data Integration & Synchronization
High – complex ETL and integration architectures
High – ongoing maintenance and monitoring
Comprehensive views; supports digital transformation
From completeness and accuracy to timeliness and traceability, we’ve covered eight key data quality issues that can significantly impact your business. Ignoring these issues isn’t an option in today’s data-driven world. Mastering these concepts, and addressing these data quality issues head-on, is crucial for making informed decisions, driving innovation, and ultimately, achieving sustainable growth. Remember, the quality of your decisions is directly tied to the quality of your data. By proactively tackling these data quality issues, you’re not just cleaning up your data; you’re setting the stage for greater efficiency, better customer experiences, and a stronger competitive edge.
High-quality data is the lifeblood of any successful modern enterprise. Whether you’re a seasoned executive, a data scientist, or an entrepreneur, understanding and addressing these issues is paramount to thriving in 2025 and beyond. It’s an investment that pays dividends across every facet of your organization.
Ready to take your data quality to the next level and unlock the true potential of your data assets? Explore how NILG.AI can help you identify, address, and prevent data quality issues, empowering you with reliable, actionable insights. Visit NILG.AI today to discover how we can help you achieve data excellence.
Special offers, latest news and quality content in your inbox.
Signup single post
Recommended Articles
Article
Transform Your Growth with custom ai software development in 2026
Apr 1, 2026 in
Guide: Explainer
Explore how custom ai software development can boost efficiency, cut costs, and deliver measurable value - find trusted partners and practical steps for 2026.
Discover how AI for customer service can transform your support operations. Learn practical strategies to reduce costs, improve satisfaction, and drive growth.
How Might We Statements: Turn Challenges into Opportunities
Mar 15, 2026 in
Guide: Explainer
Discover how might we statements transform complex challenges into real opportunities. Learn practical crafting tips, workshops, and real-world examples.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.