Let’s be honest, customer churn is a silent killer for any business. It’s the slow leak that can sink the ship. Predicting churn is all about getting ahead of that leak—using the data you already have to spot which customers are getting ready to walk away. Think of it as a critical growth strategy, because we all know it's way cheaper and smarter to keep the customers you have than to constantly chase new ones.
Why Predicting Churn Is a Business Superpower
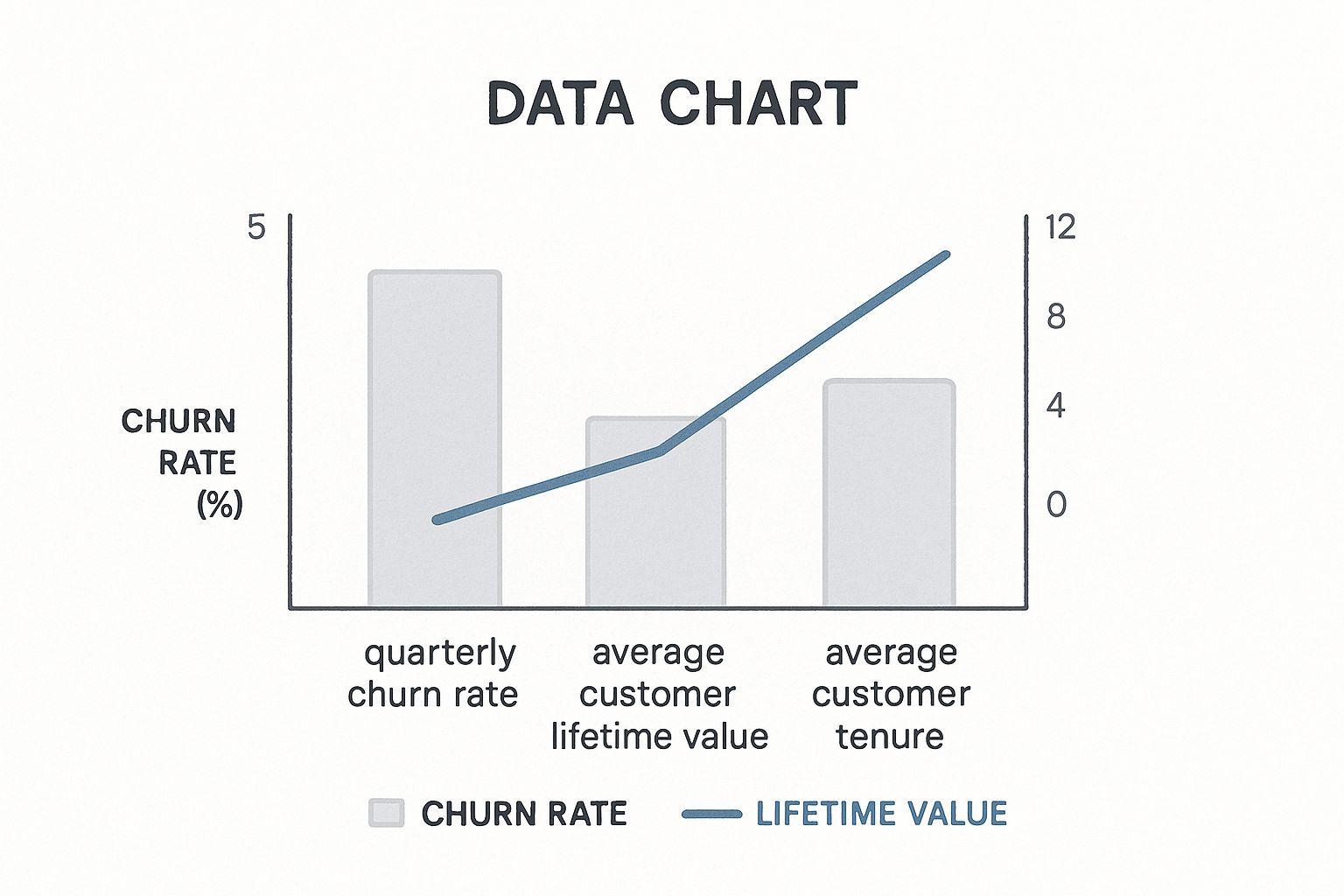
This chart really puts it into perspective, doesn't it? It’s not just a pretty graph; it shows the brutal, compounding effect that even a small churn rate has on your customer base over time. A high churn rate will bleed you dry, while a low one is the foundation for real, sustainable growth.
But let's cut through the jargon. Predicting customer churn isn't just some fancy data science experiment. For any business that relies on recurring revenue—SaaS, e-commerce, you name it—it's a fundamental shift from being reactive to proactive.
Instead of getting that dreaded "I'd like to cancel my subscription" email and scrambling, you can see the warning signs flashing weeks, or even months, in advance. That kind of foresight is a genuine business superpower.
The Tangible ROI of Proactive Retention
The business case here is a slam dunk. Churn prediction lets you put your time, energy, and money where they’ll actually make a difference. Why waste a 20% discount on a happy, loyal customer who was going to stick around anyway?
Instead, you can pinpoint the exact customers who are on the fence and give them a reason to stay. This targeted approach is where you see a massive return on your investment. Just imagine if you could:
Intervene at the perfect moment: See a user is struggling with a new feature? Automatically trigger a helpful pop-up or a quick tutorial video.
Personalize your outreach: Notice a customer’s usage has dropped off a cliff? Send them a personalized email with a special offer to re-engage them.
Gather crucial feedback: Proactively ask at-risk customers what you could be doing better before they've already made up their mind to leave.
This isn’t about throwing darts in the dark. It’s about making smart, data-driven moves to protect your revenue. These ideas are part of the bigger picture of predictive analytics for ecommerce, which is full of profitable ways to use your data.
The real magic happens when you connect a high churn-risk score to an automated, personalized retention campaign. This is how you scale customer relationships and build a more resilient business.
A Growing Market for a Critical Need
There’s a reason the market for churn analysis tools is exploding. Businesses are waking up to how critical this is. The global Customer Churn Analysis Software Market was valued at around USD 1.5 billion in 2023 and is on track to hit USD 4.2 billion by 2033.
This boom is driven by a simple, well-known truth: acquiring a new customer can cost five times more than keeping an existing one. Ouch.
Even a tiny improvement in your churn rate can have a huge impact on your bottom line. For subscription companies, this means higher Customer Lifetime Value (CLV) and the predictable revenue everyone dreams of. If this is new territory for you, getting the basics down is a must. We put together a great https://nilg.ai/202101/an-overview-of-churn-prediction/ in another article that can get you started. Ultimately, this shift to proactive retention is what separates the high-growth companies from the ones forever stuck on the customer acquisition treadmill.
Gathering the Right Data for Your Churn Model
Any great predictive model is built on a foundation of great data. It's a simple truth. If you feed it garbage, you'll get garbage out. When it comes to predicting churn, the quality and relevance of your customer data are everything.
This isn't about a frantic data grab, pulling every customer detail you can find into a massive spreadsheet. It's a much more deliberate process of sourcing the right data, cleaning it up, and then shaping it into signals that actually point to whether a customer will stick around.
Let's be real: customer data in the wild is messy. It's often scattered across different tools, full of gaps, and plagued by inconsistencies. Facing this head-on is your first—and arguably most critical—task. Get this right, and everything else falls into place.
Sourcing Your Key Data Ingredients
To really understand why a customer might leave, you need a complete picture of their journey with you. This means blending data from a few different places to build that full view.
First up, you have the basics: user attributes and demographic data. This stuff gives you context on who your customers are.
Account Info: Think plan type (Free, Pro, Enterprise), when they signed up, or the size of their company.
Demographics: Details like their geographic location or industry can sometimes uncover hidden patterns, especially if your product has stronger appeal in certain markets.
Next, you need to dive into their transactional and billing history. For any subscription business, this is a goldmine. It’s the hard evidence of a customer's financial commitment.
Purchase History: Are they upgrading, downgrading, or just staying put? A customer who keeps trimming their plan is waving a pretty big red flag.
Payment Events: Failed payments and expired credit cards are classic warning signs of what's known as involuntary churn.
Finally, and most importantly, you have behavioral and engagement data. This is where the real story is. It tells you what customers are actually doing inside your product, making it the most powerful predictor of all.
Product Usage: How often do they log in? Which features do they live in? And maybe more telling, which sticky features are they completely ignoring?
Support Interactions: Watch out for a sudden jump in support tickets from a normally quiet customer. That's a huge signal.
Onboarding Completion: Did they ever finish the key setup steps? A user who bails on onboarding is a massive churn risk from day one.
I see so many teams get hung up on demographics—who the customer is—while missing the bigger picture of what they do. Trust me, a user's actions inside your product will almost always tell you more than their profile data ever will.
The Art of Feature Engineering
Once you've wrangled all your raw data, the real fun begins. It’s time for feature engineering. This is where you get creative and turn those raw data points into much smarter signals (or 'features') that your model can actually learn from. It’s less about fancy algorithms and more about applying your own business insights.
For instance, instead of just using a "last login date," you can create a far more potent feature like "days since last seen." That simple tweak transforms a static date into a dynamic score that screams declining engagement.
Here are a few more practical examples from my experience:
Usage Ratios: Don't just count active features. Calculate the ratio of features they use versus what's available in their plan. This measures the depth of their adoption.
Trend Analysis: A single number, like "5 support tickets this month," is okay. But what's better is calculating the change in ticket volume over the last three months. A rising trend is what you're really looking for.
Combined Features: Blend different data types. For example, combine transactional data with usage data to create a feature like "value per session." This helps you spot high-value customers whose engagement is starting to slip.
This process is also your first step toward a more sophisticated understanding of customer lifetime value. By engineering features that capture deep engagement, you’re already building the blocks for better CLV models. You can actually read more on how embedding domain knowledge is crucial for estimating customer lifetime value in another one of our articles.
Ultimately, feature engineering is where your team's unique expertise shines. You’re turning generic data into sharp, predictive insights that no off-the-shelf solution could ever replicate.
Picking the Right Machine Learning Model
Alright, your data is prepped and your features are ready to go. Now comes the fun part: choosing the machine learning model that will actually power your churn prediction engine. This is where we pick the right tool to sift through all that customer data and spot the subtle clues that someone might be about to leave.
Don't get bogged down by the jargon. Think of it like this: sometimes you need a simple, reliable hammer, and other times you need a sophisticated power tool. The best choice depends entirely on what you're trying to build, balancing raw power with how easy it is to understand what's happening.
This is a good time to remember why we're doing this. The goal is to keep valuable customers around longer.
This visual drives home the relationship between key metrics. As a customer stays with you longer (tenure), their value skyrockets, and the churn rate for that cohort drops. Your model’s job is to catch the people who are about to fall off that curve before it’s too late.
The Big Trade-Off: Accuracy vs. Clarity
When you're choosing a model, you’ll immediately face a classic trade-off: accuracy versus interpretability.
Accuracy is simple: how good is the model at correctly predicting who will churn?
Interpretability is about the why: can you easily understand the logic behind the model's predictions?
Some models are "black boxes"—they might be incredibly accurate, but they give you zero insight into their reasoning. This isn't just a technical choice; it's a business one. Do you just want a list of at-risk customers handed to you, or do you need to explain to the marketing team why a certain group is likely to churn so they can build a better campaign?
For most businesses, especially when starting out, I always suggest prioritizing clarity. You can always get more complex later.
Your First Model: Start with a Solid Baseline
For your first crack at this, my go-to recommendation is almost always Logistic Regression. It’s the trusty, reliable workhorse of machine learning. It's fast, straightforward, and, most importantly, incredibly easy to interpret.
Here’s how it works in a nutshell: Logistic Regression looks at each of your features (like "days since last purchase" or "number of support tickets") and assigns a simple weight to it. A positive weight means that feature increases churn risk; a negative weight means it lowers it.
The result is a clear, simple formula that practically screams, "Here are the top 3 reasons our customers are leaving!" That kind of clarity is pure gold for getting buy-in from other departments.
When You Need a Little More Horsepower
But let's be real—customer behavior isn't always simple. Sometimes, the reasons people churn are tangled up in complex patterns that a basic model just won't catch. This is when you need to bring out the bigger guns.
Models like Random Forest and Gradient Boosting Machines (GBMs) are the industry standard when you need higher accuracy. They can uncover much more nuanced relationships in your data. For instance, maybe a high number of support tickets is a major red flag for new users but is actually a sign of deep engagement for your power users. These advanced models can spot that distinction.
The catch? This power comes at the cost of simplicity. Trying to explain exactly why a GBM flagged a specific customer can be a real headache. You're trading some of the "why" for a more accurate "who."
While Logistic Regression is a fantastic starting point, many teams eventually move on. More powerful models like Random Forest and GBMs are often chosen for their superior ability to capture these complex customer behaviors, which fuels much more effective retention strategies. If you want to dive deeper, you can learn more about the top ML models for churn prediction and see which one fits your specific situation.
Comparing Churn Prediction Models
So, which model is the right one for you? It really depends on your team's skills, your business goals, and where you are in your data science journey. There's no single "best" answer, but this table should help you weigh the options.
Model
Best For
Pros
Cons
Logistic Regression
Getting started and establishing a clear baseline.
Highly interpretable and easy to explain. Fast to train.
May miss complex, non-linear patterns in your data.
Random Forest
Achieving higher accuracy with good stability.
Handles complex data well and is less prone to overfitting.
Less interpretable than simpler models.
Gradient Boosting
Squeezing out the maximum possible accuracy.
Often the top-performing model in competitions. Excellent with large, complex datasets.
Can be slow to train and even harder to interpret. Requires careful tuning.
My advice is almost always the same: start with Logistic Regression. Build it, test it, and really listen to what it tells you about your customers. This will give you a rock-solid baseline and invaluable insights you can act on immediately. Once that's in place, you can start experimenting with a Random Forest or GBM to see if the extra boost in accuracy is worth the trade-off in clarity for your business.
Training and Validating Your Churn Model
Alright, your data is clean and you’ve picked a model. Now for the fun part. This is where we actually teach the machine to spot the warning signs of a customer about to leave. We call this "training," and it's essentially where the model pores over your historical data to learn the subtle patterns you worked so hard to prepare.
But hold on. You can't just dump all your data in at once and cross your fingers. If you want a tool that actually predicts the future—and not just regurgitates the past—you need to be clever about how you test it. This means using a critical technique to stop your model from simply "memorizing" the answers.
The Art of Splitting Your Data
Before you start training, you absolutely have to split your dataset into two, sometimes three, distinct piles. The main two are the training set and the testing set.
Think of it like this: the training set is an open-book exam. Your model can study this data inside and out, learning all the connections between customer actions and the eventual churn.
The testing set, on the other hand, is the final, closed-book exam. The model has never seen this data. By unleashing it on this unseen data, you get a real, honest grade on how it will perform with new customers down the line. A common split I’ve seen work well is 80% for training and 20% for testing.
The single biggest mistake I see teams make is not holding back a clean, untouched testing set. It's tempting to use all your data to train a "smarter" model, but you'll have no honest way to know if it actually works.
Measuring What Matters Most
So, your model has made its predictions on the test data. How do we know if it did a good job? Just looking at overall accuracy—the raw percentage of correct predictions—is a classic trap when it comes to churn.
For example, if only 2% of your customers churn each month, a lazy model that just predicts no one will churn is technically 98% accurate. It’s also completely useless.
This is why we have to dig deeper with more meaningful metrics.
Precision: Out of all the customers your model flagged as "at-risk," how many actually left? High precision means your retention team isn't wasting time and money on happy, loyal customers.
Recall (or Sensitivity): Out of all the customers who really did churn, how many did your model catch? High recall is crucial for not letting revenue slip through the cracks.
Balancing Precision and Recall
Now comes the big business decision, and it's one you have to make consciously. What's the worse mistake for your company?
A False Positive: You flag a happy customer as a churn risk (this is a low precision problem). The consequence? You might annoy them with a discount they didn't need.
A False Negative: You completely miss a customer who was heading for the door (this is a low recall problem). The consequence? You lose that customer and their revenue, probably forever.
For most companies I've worked with, the cost of a false negative is way higher. It's almost always better to catch more potential churners, even if it means a few loyal customers get an unnecessary "we miss you" email. Because of this, we often optimize for higher recall.
The F1-Score is a handy metric that balances both precision and recall into a single score. It’s a great way to quickly compare which model or which set of tweaks is performing better overall.
Once you have these numbers, the real work begins. It’s an iterative loop of tweaking the model’s settings, trying out new features, or even swapping out the algorithm entirely. You keep refining until you have a model that delivers reliable, actionable insights that your retention team can actually use to make a difference.
From Churn Scores to Saved Customers
So, you’ve got your churn model running. That's a huge step. But a prediction is just a number until you actually do something with it. Generating a list of at-risk customers is the data science piece; turning that list into saved revenue? That's where business strategy and automation come into play. This is the moment your model stops being an analytical exercise and becomes a genuine, money-making (or money-saving) retention machine.
The mission is simple: when your model flags a customer with a high churn score, you need to intervene. Fast. But what does that intervention look like? Let's be clear: a one-size-fits-all email blast won't cut it. The right move depends entirely on why that specific customer is thinking about leaving.
Taking Action Automatically
The real magic happens when you stop emailing spreadsheets around and start plugging your churn scores directly into the tools your team lives in every day—your CRM, your marketing automation platform, you name it. This is how you make retention efforts scalable.
Forget about your data team handing over a static list once a month. Picture this instead: a customer's churn score crosses a certain threshold, and it instantly kicks off a pre-defined workflow. This isn’t some far-off fantasy; it’s a totally achievable setup.
This integration is a core part of what makes applying machine learning in business analytics so powerful. You shift from just knowing something to actively doing something with that knowledge, automatically.
Building Your Retention Playbook
Alright, so what specific actions should you trigger? Your strategy here needs to be layered and smart. The response for a brand-new user fumbling through onboarding should look completely different from the one for a long-time power user whose engagement suddenly cratered.
Here are a few practical, real-world plays you can set up:
The Quiet User: A customer's login frequency drops off a cliff. Instead of a desperate "We miss you!" email, trigger a helpful one. "Did you know you could do X? Here are 3 new ways to get more from our product." Showcase features they haven't touched yet.
The Frustrated User: You see a spike in support tickets followed by radio silence. Huge red flag. This is when a human touch is worth its weight in gold. Automatically create a task in your CRM for their account manager to call them personally. A simple, "I saw you ran into some trouble last week, just wanted to check in and see if I could help" can work wonders.
The Price-Conscious Customer: If your model flags users who are sensitive to price, you can build a surgical campaign. When their score gets high, automatically add them to a special audience that gets a limited-time offer on an annual plan. This keeps you from giving discounts to happy customers who would have paid full price anyway.
My Favorite Pro Tip: Don't just act—listen. For some high-risk, high-value customers, the best first move is a simple, one-question survey: "What's the one thing we could do to make our product better for you?" The answers you get are pure gold for your product roadmap and your retention efforts.
Once your churn prediction model is dialed in, the next step is to implement effective strategies to reduce customer churn and stop customers from walking away. This is where your data finally translates into tangible business results.
Don't Forget the Feedback Loop
Lastly, every single interaction is a chance to get smarter. The outcomes of your retention campaigns—who stayed, who left, who took the discount—are incredibly valuable data points.
This information absolutely must be fed back into your system to refine your model. Did your special offer save a certain segment? Awesome, that’s a powerful signal. Did your proactive customer success outreach fail to move the needle for another group? That’s also a critical insight.
This creates a powerful feedback loop. Your churn model doesn't just get better at predicting who will churn; it starts to learn which retention tactics actually work for different types of customers. This continuous improvement cycle is what separates a decent churn prediction system from a truly great one.
Common Questions About Predicting Customer Churn
Diving into churn prediction for the first time brings up a lot of questions. That’s completely normal. This isn't just about crunching numbers; it's a strategic shift in how you understand and keep your customers. Let's walk through some of the most common things people ask, so you can move forward with confidence.
How Much Historical Data Do I Really Need to Start?
This is probably the number one question I get, and the honest answer is there's no magic number that fits everyone. But if you're looking for a solid starting point, aim for at least 6 to 12 months of consistent customer data. This gives your model enough runway to learn real patterns and see past any seasonal flukes in your business cycle.
What's arguably more important than the time frame is the quality and richness of that data. You absolutely need a good mix of customers who stayed and customers who left. If your churn rate is super low (which is a great problem to have!), you might actually need a longer history just to collect enough "churned" examples for the model to learn from.
My advice? Just start with what you have. Don't let the hunt for the "perfect" dataset become an excuse for not starting at all. You can always feed your model more data and make it smarter over time.
The goal is to give the model enough information to spot the real signals that someone is about to walk away. And that brings us to the next big question.
What Are the Best Metrics to Track for Churn?
While it’s tempting to look at demographics, the real gold is in behavioral data. What a customer does is a much stronger predictor of churn than who they are.
Your focus should be locked on these kinds of metrics:
Usage Frequency: This is your bread and butter. Are they logging in daily? Weekly? Or have they ghosted you? Simple metrics like "daily active use" are your foundation.
Feature Adoption: It's not just about showing up; it's what they do when they're there. You need to know if they're using your "sticky" features—the ones that correlate with long-term happiness.
Support Interactions: A normally quiet customer suddenly blowing up your support chat is a classic red flag. It’s often a sign of growing frustration.
Last Seen Date: So simple, yet so powerful. The more time that passes since a user's last login or interaction, the higher their churn risk climbs.
For any subscription business, add billing events to this list. Things like failed payments or downgrading a plan are huge tells. The best models weave these behavioral signals together with transactional data to get the full story.
How Often Should I Retrain My Churn Model?
A churn model is not a Crock-Pot; you can't just set it and forget it. Its accuracy will naturally fade as your product changes, your customers evolve, and market conditions shift. The features that mattered a year ago might be irrelevant today.
For most businesses, retraining your model every 3 to 6 months is a good rhythm to get into.
But this isn't a strict rule. The right timing really depends on how fast your business moves. A nimble startup pushing out new features every other week might need to retrain monthly. A more established company could be perfectly fine with a refresh every six months.
The best practice is to keep an eye on your model's performance. When you see a noticeable dip in its predictive power—like if its precision or recall drops below a certain threshold—that's your cue. It's time to feed it fresh data and get it back in shape.
Can I Predict Churn Without a Data Science Team?
Absolutely. Not too long ago, this was purely the domain of data scientists, but that's changed. The barrier to entry has dropped dramatically.
Many of today's Customer Data Platforms (CDPs) and even some high-end CRMs come with built-in, "no-code" churn prediction features. These tools are designed to do the heavy lifting for you, handling things like data prep and model training behind the scenes. You get the insights without needing to know the first thing about machine learning algorithms.
It's a fantastic way to prove the concept and show the value of proactive retention. You can start flagging at-risk customers and saving revenue immediately, which often builds a strong case for investing in a more custom solution later on.
Ready to turn your customer data into a powerful retention engine? At NILG.AI, we specialize in building AI solutions that reduce inefficiencies and drive growth. From AI strategy to predictive analytics, we provide a clear roadmap to transform your business challenges into opportunities. Discover how our tailored AI solutions can help you predict and prevent customer churn.
Master customer retention rate calculation with this practical guide. Learn the formulas, see real-world examples, and get actionable tips for business growth.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.